linux
shell变量含义
- $# 是传给脚本的参数个数
- $0 是脚本本身的名字
- $1 是传递给该shell脚本的第一个参数
- $2 是传递给该shell脚本的第二个参数
- $3 是传递给该shell脚本的第三个参数
- $@ 是传给脚本的所有参数的列表
- $* 是以一个单字符串显示所有向脚本传递的参数,与位置变量不同,参数可超过9个
- $$ 是脚本运行的当前进程ID号
- $? 是显示最后命令的退出状态,0表示没有错误,其他表示有错误
es修复分片
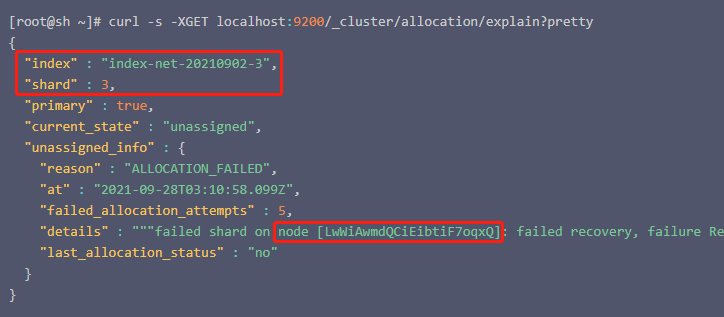
通过explain api查看详细情况
[root@sh ~]# curl -s -XGET localhost:9200/_cluster/allocation/explain?pretty
{
"index" : "index-net-20210902-3",
"shard" : 3,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "ALLOCATION_FAILED",
"at" : "2021-09-28T03:10:58.099Z",
"failed_allocation_attempts" : 5,
"details" : """failed shard on node [LwWiAwmdQCiEibtiF7oqxQ]: failed recovery, failure RecoveryFailedException[[device_search_20201204][3]: Recovery failed on {reading_9.10.126.164_node2}{LwWiAwmdQCiEibtiF7oqxQ}{YVadGK2FSDKbR69l0Wu0xg}{9.10.126.164}{9.10.126.164:9300}{dil}{ml.machine_memory=539647844352, xpack.installed=true, ml.max_open_jobs=20}]; nested: IndexShardRecoveryException[failed recovery]; nested: ElasticsearchException[java.io.IOException: failed to read /data1/containers/1612339152002810932/es/data/nodes/0/indices/b0Ar9gFpQc6_oHhrdHYxGQ/7/_state/retention-leases-1518.st]; nested: IOException[failed to read /data1/containers/1612339152002810932/es/data/nodes/0/indices/b0Ar9gFpQc6_oHhrdHYxGQ/7/_state/retention-leases-1518.st]; nested: IOException[org.apache.lucene.index.CorruptIndexException: codec footer mismatch (file truncated?): actual footer=892219961 vs expected footer=-1071082520 (resource=BufferedChecksumIndexInput(SimpleFSIndexInput(path="/data1/containers/1612339152002810932/es/data/nodes/0/indices/b0Ar9gFpQc6_oHhrdHYxGQ/7/_state/retention-leases-1518.st")))]; nested: CorruptIndexException[codec footer mismatch (file truncated?): actual footer=892219961 vs expected footer=-1071082520 (resource=BufferedChecksumIndexInput(SimpleFSIndexInput(path="/data1/containers/1612339152002810932/es/data/nodes/0/indices/b0Ar9gFpQc6_oHhrdHYxGQ/7/_state/retention-leases-1518.st")))]; """,
"last_allocation_status" : "no"
}
}
方案一:修复分片
retention-leases-1518.st 这个文件的损坏,与这个文件曾经有一段时间不在线有关系。也就是说,与机器重启有关。如果要恢复的话,则需要手动删除这个文件,然后重新尝试分配分片:
[root@sh ~]# curl -s -XPOST localhost:9200/_cluster/reroute?retry_failed=true
{
"acknowledged": true,
"state": {
"cluster_uuid": "LOk2L8k5RsmCC7eg2y3h8A",
"version": 533752,
"state_uuid": "jVm_8aAIT6ug9NBJazjVig",
"master_node": "kHbBiclxR5-c-rsra2A5Jg",
"blocks": {
},
"nodes": {
"m5eloUNuTJak4xDRqf3FeA": {
"name": "1625799512002116132",
"ephemeral_id": "dqHmYahLSbuqvSkRXy2IPg",
"transport_address": "9.27.34.96:9300",
"attributes": {
"ml.machine_memory": "134587404288",
"rack": "cvm_33_330002",
"xpack.installed": "true",
"set": "330002",
"transform.node": "true",
"ip": "9.27.34.96",
"temperature": "hot",
"ml.max_open_jobs": "20",
"region": "33"
}
},
"security_tokens": {
}
}
}
方案二:分配陈腐的分片
如果删除损坏的.st文件无法使分片上线,则需要考虑使用reroute api分配stale primary。执行这个api之前,我们需要得到一些信息:
- 索引名称和分片ID可以通过
explain api直观看到; - 节点名称可以通过
unassigned_info.details得到。
根据这些信息,我们就可以执行reroute api了:
[root@sh ~]# curl -s -H "Content-Type:application/json" -XPOST "localhost:9200/_cluster/reroute?pretty" -d '
{
"commands": [
{
"allocate_stale_primary": {
"index": "{索引名称}",
"shard": "{分片ID}",
"node": "{节点名称}",
"accept_data_loss": true
}
}
]
}
方案三:丢弃分片
如果分配陈腐的分片也无法使分片上线,为了不影响索引读写请求,就只能丢弃掉损坏的分片了,这是最糟糕的情况:
[root@sh ~]# curl -s -H "Content-Type:application/json" -XPOST "localhost:9200/_cluster/reroute?pretty" -d '
{
"commands" : [
{
"allocate_empty_primary" : {
"index" : "{索引名称}",
"shard" : "{分片ID}",
"node" : "{节点名称}",
"accept_data_loss": true
}
}
]
}'
使用Lucene CheckIndex 修复
-exorcise只能在紧急情况下使用,因为它将导致文件(也许是很多)被永久地从索引中删除。
- 在运行这个工具之前,一定要对你的索引做一个备份。
- 不要在一个正在被写入的索引上运行这个工具。
java -cp /usr/share/elasticsearch/lib/lucene-core-7.5.0.jar -ea:org.apache.lucene... org.apache.lucene.index.CheckIndex /work/elasticsearch/data/nodes/0/indices/uYrH-t7AR7e5mR2eCC7-6g/2/index -verbose -exorcise
结果返回 No problems were detected with this index. 话,说明索引没有损坏直接移除目录下的数据损坏标签 corrupted_*文件然后重启es
mv /work/elasticsearch/data/nodes/0/indices/uYrH-t7AR7e5mR2eCC7-6g/2/index/corrupted_H_wQlkOtQzKaz3dGkq_G-A /tmp
链接:
haproxy停用启用server
设置socket admin权限
stats socket /var/lib/haproxy/stats level admin
停用backend app下的server app1
echo "disable server app/app1" | socat stdio /var/lib/haproxy/stats
启用
echo "enable server app/app1" | socat stdio /var/lib/haproxy/stats
mysql导出文件
msyql5.7 secure_file_priv 用于限制数据导入导出操作:
- secure_file_priv 为 NULL 时,表示限制mysqld不允许导入或导出。
- secure_file_priv 为 /tmp 时,表示限制mysqld只能在/tmp目录中执行导入导出,其他目录不能执行。
- secure_file_priv 没有值 时,表示不限制mysqld在任意目录的导入导出。
因为 secure_file_priv 参数是只读参数,不能使用set global命令修改。需要在my.ini里加入 secure_file_priv='' 。
查看当前配置:
show global variables like '%secure_file_priv%';
导出csv:
select * from user into outfile '/tmp/user.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n';
导入数据:
load data local infile '/tmp/data.txt' replace into table mytable;
xtrabackup备份
yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install -y percona-xtrabackup-21.x86_64
备份:
创建备份用户
create user 'bakuser'@'localhost' identified by '123456';
grant reload, lock tables, process, replication client on *.* to 'bakuser'@'localhost';
flush privileges;
全量备份
xtrabackup -u bakuser -p 123456 --backup --target-dir=/data/dbbak/base
压缩备份
xtrabackup --backup --compress --compress-threads=4 --target-dir=/data/dbbak/base
备份指定数据库
xtrabackup -u bakuser -p 123456 --databases="db1 db2" --backup --target-dir=/data/dbbak/base
备份指定表
xtrabackup -u bakuser -p 123456 --databases="db1.tab1 db2.tab2" --backup --target-dir=/data/dbbak/base
恢复:
准备备份
#压缩过的需要先解压缩
xtrabackup --decompress --target-dir=/data/dbbak/base
xtrabackup --prepare --target-dir=/data/dbbak/base
恢复备份 --move-back 移动不保留备份 --copy-back 复制保留备份
#rsync -avrP /data/dbbak/base/ /var/lib/mysql/
xtrabackup --copy-back --target-dir=/data/dbbak/base
chown -R mysql:mysql /var/lib/mysql
增量备份:
创建全量备份
xtrabackup -u bakuser -p 123456 --backup --target-dir = /data/dbbak/base
创建增量备份 inc1
xtrabackup -u bakuser -p 123456 --backup --target-dir=/data/dbbak/inc1 --incremental-basedir=/data/dbbak/base
创建增量备份 inc2
xtrabackup -u bakuser -p 123456 --backup --target-dir=/data/dbbak/inc2 --incremental-basedir=/data/dbbak/inc1
恢复增量备份:
准备备份
#压缩过的需要先解压缩
xtrabackup --decompress --target-dir=/data/dbbak/base
xtrabackup --prepare --apply-log-only --target-dir=/data/dbbak/base
xtrabackup --prepare --apply-log-only --target-dir=/data/dbbak/base --incremental-dir=/data/dbbak/inc1
xtrabackup --prepare --target-dir=/data/dbbak/base --incremental-dir=/data/dbbak/inc2
恢复备份
#rsync -avrP /data/dbbak/ /var/lib/mysql/
xtrabackup --copy-back --target-dir=/data/dbbak/
chown -R mysql:mysql /var/lib/mysql
恢复单个表:
yum install mysql-utilities -y
#从备份中读取表结构 复制创表语句在数据库创建表
mysqlfrm --diagnostic /data/dbbak/mydb/tb1.frm
#丢弃表空间
alter table tb1 discard tablespace;
#从备份中拷贝ibd文件
cp /data/dbbak/mydb/tb1.ibd /var/lib/mysql/mydb/
chown mysql. /var/lib/mysql/mydb/tb1.ibd
#载入表空间
alter table tb1 import tablespace;
链接:
- https://www.jianshu.com/p/19b986a39b5e
- https://www.percona.com/doc/percona-xtrabackup/2.4/index.html#advanced-features
- https://www.percona.com/doc/percona-xtrabackup/2.3/howtos/recipes_ibkx_stream.html
linux中文支持
centos
yum -y install fontconfig
#查看已安装的中文字体
fc-list :lang=zh
#安装中文字体
yum install wqy-zenhei-fonts wqy-microhei-fonts
#刷新字体缓存
fc-cache -f -v
debian
#查看当前环境语言
locale
#安装中文字体
apt-get install xfonts-wqy ttf-wqy-zenhei ttf-wqy-microhei
#添加中文环境支持
dpkg-reconfigure locales
#通过空格选择 选择后确认添加
#zh_CN,UTF-8 UTF-8
ubuntu
# 安装中文字体
apt install fonts-wqy-microhei ttf-wqy-zenhei
#生成中文环境
sudo locale-gen zh_CN.UTF-8
#输入法
#安装输入法
sudo apt install fcitx fcitx-googlepinyin
#生成dbus机器码
dbus-uuidgen > /var/lib/dbus/machine-id
#配置环境变量,/etc/profile.d/fcitx.sh
#!/bin/bash
export QT_IM_MODULE=fcitx
export GTK_IM_MODULE=fcitx
export XMODIFIERS=@im=fcitx
export DefaultIMModule=fcitx
fcitx-autostart &>/dev/null
#配置 Fcitx 的输入法选项
fcitx-config-gtk3
#运行fcitx
fcitx-autostart
logrotate日志切割
logrotate 是基于 cron 每天运行
配置文件示例:
/var/log/zabbix/zabbix_agentd.log {
weekly
rotate 12
compress
delaycompress
missingok
notifempty
create 0664 zabbix zabbix
}
/var/log/cron
/var/log/maillog
/var/log/messages
/var/log/secure
/var/log/spooler
{
missingok
sharedscripts
postrotate
/bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
endscript
}
/var/log/httpd/*log {
missingok
notifempty
sharedscripts
delaycompress
postrotate
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
endscript
}
/var/log/tinyproxy/tinyproxy.log {
daily
rotate 10
missingok
notifempty
compress
sharedscripts
postrotate
[ ! -f /var/run/tinyproxy/tinyproxy.pid ] || kill -HUP `cat /var/run/tinyproxy/tinyproxy.pid`
endscript
}
- monthly: 日志文件将按月轮循。其它可用值为 daily,weekly 或者 yearly。
- rotate 5: 一次将存储 5 个归档日志。对于第六个归档,时间最久的归档将被删除。
- compress: 在轮循任务完成后,已轮循的归档将使用 gzip 进行压缩。
- delaycompress: 总是与 compress 选项一起用,delaycompress 选项指示 logrotate 不要将最近的归档压缩,压缩 将在下一次轮循周期进行。这在你或任何软件仍然需要读取最新归档时很有用。
- missingok: 在日志轮循期间,任何错误将被忽略,例如 “文件无法找到” 之类的错误。
- notifempty: 如果日志文件为空,轮循不会进行。
- create 644 root root: 以指定的权限创建全新的日志文件,同时 logrotate 也会重命名原始日志文件。
- postrotate/endscript: 在所有其它指令完成后,postrotate 和 endscript 里面指定的命令将被执行。在这种情况下,rsyslogd 进程将立即再次读取其配置并继续运行。
常用配置参数:
- daily :指定转储周期为每天
- weekly :指定转储周期为每周
- monthly :指定转储周期为每月
- rotate count :指定日志文件删除之前转储的次数,0 指没有备份,5 指保留 5 个备份
- tabooext [+] list:让 logrotate 不转储指定扩展名的文件,缺省的扩展名是:.rpm-orig, .rpmsave, v, 和~
- missingok:在日志轮循期间,任何错误将被忽略,例如 “文件无法找到” 之类的错误。
- size size:当日志文件到达指定的大小时才转储,bytes (缺省) 及 KB (sizek) 或 MB (sizem)
- compress: 通过 gzip 压缩转储以后的日志
- nocompress: 不压缩
- copytruncate:用于还在打开中的日志文件,把当前日志备份并截断
- nocopytruncate: 备份日志文件但是不截断
- create mode owner group : 转储文件,使用指定的文件模式创建新的日志文件
- nocreate: 不建��立新的日志文件
- delaycompress: 和 compress 一起使用时,转储的日志文件到下一次转储时才压缩
- nodelaycompress: 覆盖 delaycompress 选项,转储同时压缩
- errors address : 专储时的错误信息发送到指定的 Email 地址
- ifempty :即使是空文件也转储,这个是 logrotate 的缺省选项
- notifempty :如果是空文件的话,不转储
- mail address : 把转储的日志文件发送到指定的 E-mail 地址
- nomail : 转储时不发送日志文件
- olddir directory:储后的日志文件放入指定的目录,必须和当前日志文件在同一个文件系统
- noolddir: 转储后的日志文件和当前日志文件放在同一个目录下
- prerotate/endscript: 在转储以前需要执行的命令可以放入这个对,这两个关键字必须单独成行
pm2
fork模式:单实例多进程不支持端口复用。支持配置interpreter使用pm2运行js之外的语言,例如php、python等等。
cluster模式:多实例多进程,只支持node,端口可以复用,实现负载均衡、共享TCP连接。
npm install -g pm2
常用命令:
-
npm启动
pm2 start npm --name "myapp" -- start -
npm启动指定脚本
pm2 start npm --name "myapp" -- run "start:dev" -
指定参数启动
pm2 start app.js --node-args="--max-old-space-size=1024" -
启动app.js应用程序
pm2 start app.js -
启动4个app.js的应用实例cluster模式
pm2 start app.js -i 4 -
启动应用程序并命名为myapp
pm2 start app.js --name="myapp" -
当文件变化时自动重启应用
pm2 start app.js --watch -
通过config文件启动
pm2 start ecosystem.config.js -
列出 PM2 启动的所有的应用程序
pm2 list -
显示每个应用程序的CPU和内存占用情况
pm2 monit -
显示应用程序的所有信息
pm2 show [app-name] -
显示所有应用程序的日志
pm2 logs -
显示指定应用程序的日志
pm2 logs [app-name] -
清空所有日志
pm2 flush -
停止所有的应用程序
pm2 stop all -
停止 id为 0的指定应用程序
pm2 stop 0 -
重启所有应用
pm2 restart all -
重新加载所有应用
pm2 reload all -
关闭并删除所有应用
pm2 delete all -
删除指定应用 id 0
pm2 delete 0 -
把应用扩展到10个实例
pm2 scale [app-name] 10 -
增加2个实例
pm2 scale [app-name] +2 -
重置重启次数
pm2 reset [app-name] -
创建开机自启动命令
pm2 startup -
保存当前应用列表
pm2 save -
更新pm2 ,保存进程>杀死PM2>恢复进程
pm2 update -
生成ecosystem.config.js模板
pm2 initpm2 init simplepm2 ecosystem
module.exports = {
apps : [{
name: 'myapp', // 项目名
script: 'index.js', // 执行文件
cwd: './', // 工作目录
args: '', // 传递给脚本的参数
interpreter: '/usr/bin/python', // 指定的脚本解释器,默认node
interpreter_args: '', // 传递给解释器的参数
watch: '.', // 是否监听文件变动然后重启
ignore_watch: [ // 不用监听的文件或目录
'node_modules,
'logs'
],
exec_mode: 'fork', // 启动应用程序的模式,可以是cluster或fork,默认fork。
instances: 4, // 应用启动实例个数
max_memory_restart: '8G', // 最大内存限制数,超出自动重启
error_file: './logs/app-err.log', // 错误日志文件
out_file: './logs/app-out.log', // 正常日志文件
merge_logs: true, // 设置追加日志而不是新建日志
log_date_format: 'YYYY-MM-DD HH:mm:ss', // 指定日志文件的时间格式
min_uptime: '60s', // 应用运行少于时间被认为是异常启动
max_restarts: 30, // 最大异常重启次数,即小于min_uptime运行时间重启次数;
autorestart: true, // 默认为true, 发生异常的情况下自动重启
cron_restart: '1 0 * * *', // crontab时间格式重启应用;
restart_delay: '60s' // 异常重启情况下,延时重启时间
env: { // 默认环境参数
PORT: 3003,
NODE_ENV: 'production',
MYNAME: 'aa'
},
env_dev: { // 自定义环境参数dev,当前指定为开发环境 pm2 start app.js --env dev
NODE_ENV: 'development',
MYNAME: 'bb'
},
env_test: { // 自定义环境参数test,当前指定为测试环境 pm2 start app.js --env test
NODE_ENV: 'test',
MYNAME: 'cc'
}
}, {
script: './service-worker/',
watch: ['./service-worker']
}],
deploy : {
production : {
user : 'SSH_USERNAME',
host : 'SSH_HOSTMACHINE',
ref : 'origin/master',
repo : 'GIT_REPOSITORY',
path : 'DESTINATION_PATH',
'pre-deploy-local': '',
'post-deploy' : 'npm install && pm2 reload ecosystem.config.js --env production',
'pre-setup': ''
}
}
};
windwos文件名到linux乱码
安装convmv:
yum -y install convmv
转换编码:
convmv --notest --nosmart -f gbk -t utf8 -r /data
参数:
- -f enc 源编码
- -t enc 新编码
- -r 递归处理子文件夹
- -i 交互文向转换
- --list 显示所有可用编码
- --nosmart 如果是utf8文件,忽略
- --notest 直接转换不测试
- --replace 文件相同直接替换
- --unescape 可以做一下转义,比如把%20变成空格
- --upper 全部转换成大写
redis
创建集群:
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
添加节点:
-
添加master节点(master7008)
redis-cli --cluster add-node 127.0.0.1:7008 127.0.0.1:7000 -
添加slave节点(指定master-id的slave7009)
redis-cli --cluster add-node 127.0.0.1:7009 127.0.0.1:7000 --cluster-slave --cluster-master-id 46f0b68b3f605b3369d3843a89a2b4a164ed21e8
删除节点:
-
迁移哈希槽至别的节点
redis-cli --cluster reshard 127.0.0.1:7000 --cluster-from 46f0b68b3f605b3369d3843a89a2b4a164ed21e8 --cluster-to 2846540d8284538096f111a8ce7cf01c50199237 --cluster-slots 1024 --cluster-yes -
删除master以及对应的slave节点
redis-cli --cluster del-node 127.0.0.1:7000 46f0b68b3f605b3369d3843a89a2b4a164ed21e8
导入数据:
-
数据从外部实例导入到 Redis 集群
redis-cli --cluster import 127.0.0.1:7001 --cluster-from 172.16.7.14:6379 --cluster-copy -
数据从aof恢复数据到集群
redis-cli -c -p 7001 --pipe < appendonly.aof
修复槽:
[WARNING] Node 127.0.0.1:7003 has slots in migrating state 10867.
-
清除哈希槽中的任何导入/迁移状态
redis-cli -c -p 7001 cluster setslot 10867 stable -
修复(槽对应的节点)
redis-cli --cluster fix 127.0.0.1:7003
迁移槽(from & to 对应节点id):
# cluster-slots 迁移槽的数量
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from 9a243bc1db6cd60689512b2c3c63e5962b2de0bb --cluster-to 3e96051497a2021c84d230831104f1f9e8c6430a --cluster-slots 5461 --cluster-yes
redis-cli下常用操作:
redis-cli -c -p 7001
-
指定或切换当前节点为node-id的slave(master时必须迁移走所有槽)
cluster replicate node-id -
查看keyname对应的槽
cluster keyslot keyname -
查看槽的分配
cluster slots -
异步重写aof生成新的aof文件
bgrewriteaof -
异步生成rdb
bgsave
查看集群节点及槽分配
redis-cli --cluster check 127.0.0.1:7001
查看集群各节点dbsize
redis-cli --cluster call 127.0.0.1:7001 dbsize
kvm
安装kvm:
yum install -y qemu-kvm libvirt
yum install -y virt-install libvirt-python virt-manager virt-install libvirt-client
配置网桥:
virsh iface-bridge eth0 br0
virsh iface-list
brctl show
virsh iface-unbridge br0
创建虚拟机:
virt-install --name t01 --vcpus=2 --memory=1024 --location=/vm/CentOS-8.1.1911-x86_64-dvd1.iso --disk /vm/w01.qcow2,size=20,format=qcow2 --graphics vnc,listen=0.0.0.0 --noautoconsole --autostart --os-type=linux --os-variant=rhel8.0
virt-install --name eBay16_237--memory=2048 --vcpus=2 --os-type=windows --cdrom /data/en_windows_7_ultimate_with_sp1_x64_dvd_u_677332.iso --disk path=/usr/share/virtio-win/virtio-win-0.1.171_amd64.vfd,device=floppy --disk path=/data/kvm/eBay16_237.img,size=30,bus=virtio,format=qcow2 --network bridge=br0,model=virtio --graphics vnc,listen=0.0.0.0 --noautoconsole
-
从ISO映像安装虚拟机
virt-install \
--name guest1-rhel7 \
--memory 2048 \
--vcpus 2 \
--disk size=8 \
--cdrom /path/to/rhel7.iso \
--os-variant rhel7 \
--noautoconsole -
从虚拟磁盘映像导入虚拟机
virt-install \
--name guest1-rhel7 \
--memory 2048 \
--vcpus 2 \
--disk /path/to/imported/disk.qcow2 \
--import \
--os-variant rhel7 \
--noautoconsole -
从网络安装虚拟机
virt-install \
--name guest1-rhel7 \
--memory 2048 \
--vcpus 2 \
--disk size=8 \
--location http://example.com/path/to/os \
--os-variant rhel7 -
使用PXE安装虚拟机
virt-install \
--name guest1-rhel7 \
--memory 2048 \
--vcpus 2 \
--disk size=8 \
--network=bridge:br0 \
--pxe \
--os-variant rhel7 \
--noautoconsole -
使用Kickstart安装虚拟机
virt-install \
--name guest1-rhel7 \
--memory 2048 \
--vcpus 2 \
--disk size=8 \
--location http://example.com/path/to/os \
--os-variant rhel7 \
--initrd-inject /path/to/ks.cfg \
--extra-args="ks=file:/ks.cfg console=tty0 console=ttyS0,115200n8" \
--noautoconsole
在线添加硬盘:
qemu-img create -f qcow2 /data/kvm/win11_1.img 20G
virsh attach-disk win11 /data/kvm/win11_1.img vdb --driver qemu --subdriver qcow2 --targetbus virtio --persistent
卸载硬盘:
# 分离硬盘 vdb or img路径
virsh detach-disk win11 /data/kvm/win11_1.img
硬盘扩容:
# 虚拟机在关机状态下进行
qemu-img resize /data/kvm/win11.img +10G
压缩硬盘使用空间:
qemu-img convert -c -O qcow2 /data/kvm/win11_1.img /tmp/kvm/win11_1.img
DNF error: Error in POSTTRANS scriptlet in rpm package kernel-core 加上参数 --extra-args ro
lvs
ipvsadm -A -t VIP:port -s rr
ipvsadm -a -t VIP:port -r RIP1 -g
ipvsadm -a -t VIP:port -r RIP2 -g
#示例
#ipvsadm -A -t 172.16.7.14:80 -s rr
#ipvsadm -a -t 172.16.7.14:80 -r 172.16.7.15:88 -g
#ipvsadm -a -t 172.16.7.14:80 -r 172.16.7.16:81 -g
#ipvsadm -a -t 172.16.7.14:80 -r 172.16.7.17 -g
ipvsadm -A -t VIP:port -s rr
- -A 选项为添加一条虚拟服务器记录,即创建一个LVS集群
- -t 标识创建的LVS集群服务为tcp协议,VIP:port 标识集群服务IP及端口号,
- -u 使用udp协议
- -s Scheduling 调度之意,后面参数为指定的调度算法,有rr、wrr、lc、wlc、lblc、lblcr、dh、sh、sed、nq,默认为wlc,其中rr为Round-Robin缩写,代表轮询算法
ipvsadm -a -t VIP:port -r RIP -g
- -a 选项表示添加一个RS到集群中
- -t 使用tcp协议
- -u 使用udp协议
- -r 用于指定需要添加的RIP(RS对应IP)
- -g 表示LVS工作模式为DR模式,-i 为TUN模式,-m 为NAT模式
查看生效规则:
ipvsadm -Ln
但要注意一点,如果没有提前将规则进行保存,在设备重启后配置会消失,所以我们配置完需要用 service ipvsadm save 保存命令,重启后用 service ipvsadm reload 重新载入规则。除此之外,可以用 ipvsadm -S > file 将LVS规则保存在指定文件中,通过 ipvsadm -R < file 进行重载
链接:
nginx热升级版本
-
备份旧nginx
mv /usr/local/nginx/sbin/nginx{,.bak} -
编译新ningx,复制编译好的nginx到sbin下
aria2c -c -x 10 https://nginx.org/download/nginx-1.20.1.tar.gz
tar zxf nginx-1.20.1.tar.gz
cd nginx-1.20.1
./configure --prefix=/usr/local/nginx --with-http_ssl_module
make -j
cp objs/nginx /usr/local/nginx/sbin -
给旧nginx进程发送usr2信号,nginx会使用新文件启动一个新的master进程,生成新的nginx.pid文件旧的重命名为.obin
kill -usr2 `cat /usr/local/nginx/logs/nginx.pid` -
给旧nginx进程发送winch关闭旧nginx的worker进程
kill -winch `cat /usr/local/nginx/logs/nginx.pid.obin` -
待都正常后给旧nginx进程发送quit信号退出master进程
kill -quit `cat /usr/local/nginx/logs/nginx.pid.obin`
回滚(需要旧进程存在):
-
重启旧进程worker
kill -hup `cat /usr/local/nginx/logs/nginx.pid.obin` -
退出新的进程
kill -quit `cat /usr/local/nginx/logs/nginx.pid`
链接:
查看证书信息
查看过期时间:
openssl x509 -noout -enddate -in /etc/kubernetes/pki/ca.crt
查看证书信息:
openssl x509 -noout -text -in ca.crt
查看KEY信息:
openssl rsa -noout -text -in ca.key
查看CSR信息:
openssl req -noout -text -in ca.csr
kvm 开启tcp远程连接
启用tcp的端口
LIBVIRTD_CONFIG=/etc/libvirt/libvirtd.conf
LIBVIRTD_ARGS="--listen"
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
listen_addr = "0.0.0.0"
auth_tcp = "none"
连接
virsh -c qemu+tcp://172.16.7.254/system
tsl
mkdir pki
cd pki/
certtool --generate-privkey > cakey.pem
cat >ca.info <<EOF
cn = ops
ca
cert_signing_key
expiration_days = 700
EOF
# cn: 组织名称
# expiration_days:过期天数,默认1年
certtool --generate-self-signed --load-privkey cakey.pem --template ca.info --outfile cacert.pem
certtool --generate-privkey > serverkey.pem
cat > server.info <<EOF
organization = ops
cn = server22
ip_address = 172.16.7.14
tls_www_server
encryption_key
signing_key
expiration_days = 700
EOF
# organization: 组织名,和ca中的cn一致
# cn: kvm服务器的hostname,需要能ping
# ip_address: kvm服务器的ip
# expiration_days: 证书过期时间
certtool --generate-certificate --load-privkey serverkey.pem --load-ca-certificate cacert.pem --load-ca-privkey cakey.pem --template server.info --outfile servercert.pem
certtool --generate-privkey > clientkey.pem
cat >client.info <<EOF
country = CN
state = GD
locality = SZ
organization = ops
cn = server22
tls_www_server
encryption_key
signing_key
expiration_days = 700
EOF
certtool --generate-certificate --load-privkey clientkey.pem --load-ca-certificate cacert.pem --load-ca-privkey cakey.pem --template client.info --outfile clientcert.pem
cp servercert.pem /etc/pki/libvirt/
cp serverkey.pem /etc/pki/libvirt/private/
cp cacert.pem /etc/pki/CA/
scp cacert.pem root@172.16.7.14:/etc/pki/CA/
scp clientcert.pem root@172.16.7.14:/etc/pki/libvirt/clientcert.pem
scp clientkey.pem root@172.16.7.14:/etc/pki/libvirt/clientkey.pem
vim /etc/sysconfig/libvirtd
#libvirtd启动时添加--listen参数
LIBVIRTD_ARGS="--listen"
链接:
vim进入块编辑模式
wsl:ctrl+q
linux:ctrl+v or ctrl+shift+v
批量编辑内容:按方向键选中要编辑的行 shift+i 编辑输入内容然后按两下esc
安装python
debian:
apt install gcc g++ make libssl-dev libsqlite3-dev libreadline-dev libffi-dev zlib1g-dev libbz2-dev
centos:
yum install -y zlib-devel bzip2-devel readline-devel sqlite-devel openssl-devel libffi-devel
ModuleNotFoundError: No module named '_ctypes' 需要安装libffi然后重新编译
查看使用swap进程
for i in $(cd /proc;ls | grep "^[0-9]" | awk '$0>100'); do awk '/Swap:/{a=a+$2}END{print '"$i"',a/1024"M"}' /proc/$i/smaps;done| sort -k2nr | head
esxi 安装MegaCli
esxcli software vib install -v=/tmp/vmware-esx-MegaCli-8.07.06.vib -f --maintenance-mode
链接:
omsa
简介
OMSA全称为Dell OpenManage Server Administrator,专为系统管理员设计,可用于管理本地系统及网络中的远程系统。OMSA提供了一个全面的一对一系统管理解决方案包,可使系统管理员专注于整个网络的管理工作。
OMSA系统管理方案可以全面解决系统管理人员最关心的系统部署、系统监控和系统变更三大系统管理问题。它通过提供以下两种方式来对本地和远程的服务器进行管理和监控。
1、基于Web浏览器的集成图形用户界面(GUI)
2、操作系统的命令行界面(CLI)工具
安装omsa
-
完整版安装
#安装omsa的源
wget -q -O - http://linux.dell.com/repo/hardware/latest/bootstrap.cgi | bashyum -y install srvadmin-all # 安装所有软件包
yum -y install srvadmin-base # 只安装OMSA基础服务,不包括web管理
yum -y install srvadmin-omacore # 安装CLI命令
yum -y install srvadmin-webserver # 安装web管理组件
yum -y install srvadmin-storageservices # 安装RAID控制卡管理组件
yum -y install srvadmin-rac4 # 安装远程控制卡4管理组件
yum -y install srvadmin-rac5 # 安装远程控制卡5管理组件所有的软件包将被安装至/opt目录下,虽然 OMSA 的web端功能很强大,但是在工作当中,我们的主要目的并非是使用它的web端,更多时间只是想使用它提供的一些命令行工具来获取服务器主要组件的相关信息,比如CPU、内存、硬盘、陈列和主板温度之类的健康状况。因此,我们没有必要安装OMSA的web端,所以如果只是做监控,安装
srvadmin-base、srvadmin-omacore及srvadmin-storageservices即可。。 -
精简版
正常情况下,直接Yum安装即可,但是现阶段srvadmin的源在国外,下载慢,同时还有一些内网机器不能直接通外网,只能把包下载下来,然后直接安装。参考了单个组件的-rpm这里面的说明(或者https://topics-cdn.dell.com/pdf/openmanage-server-administrator-v93_install-guide2_zh-cn.pdf),制作出来了精简版的omsa 9.3.0版本。具体的rpm的安装包如下:
Updating / installing...
1:srvadmin-omilcore-9.3.0-3465.1481################################# [ 3%]
2:srvadmin-deng-9.3.0-3465.14818.el################################# [ 7%]
3:srvadmin-omacs-9.3.0-3465.14818.e################################# [ 10%]
4:srvadmin-xmlsup-9.3.0-3465.14818.################################# [ 14%]
5:srvadmin-hapi-9.3.0-3465.14818.el################################# [ 17%]
6:srvadmin-isvc-9.3.0-3465.14818.el################################# [ 21%]
7:srvadmin-sysfsutils-9.3.0-3465.14################################# [ 24%]
8:srvadmin-smcommon-9.3.0-3465.1481################################# [ 28%]
9:srvadmin-deng-snmp-9.3.0-3465.148################################# [ 31%]
10:srvadmin-isvc-snmp-9.3.0-3465.148################################# [ 34%]
11:srvadmin-ominst-9.3.0-3465.14818.################################# [ 38%]
12:srvadmin-omcommon-9.3.0-3465.1481################################# [ 41%]
13:srvadmin-omacore-9.3.0-3465.14818################################# [ 45%]
14:srvadmin-storelib-sysfs-9.3.0-346################################# [ 48%]
15:srvadmin-storelib-9.3.0-3465.1481################################# [ 52%]
16:srvadmin-realssd-9.3.0-3465.14818################################# [ 55%]
17:srvadmin-nvme-9.3.0-3465.14818.el################################# [ 59%]
18:srvadmin-marvellib-9.3.0-3465.148################################# [ 62%]
19:srvadmin-storage-9.3.0-3465.14818################################# [ 66%]
20:srvadmin-storage-cli-9.3.0-3465.1################################# [ 69%]
21:srvadmin-storageservices-cli-9.3.################################# [ 72%]
22:srvadmin-storage-snmp-9.3.0-3465.################################# [ 76%]
23:srvadmin-storageservices-snmp-9.3################################# [ 79%]
24:srvadmin-argtable2-9.3.0-3465.148################################# [ 83%]
25:libsmbios-2.3.3-8.el7 ################################# [ 86%]
26:smbios-utils-bin-2.3.3-8.el7 ################################# [ 90%]
27:srvadmin-idracadm7-9.3.0-3465.148################################# [ 93%]
28:srvadmin-storageservices-9.3.0-34################################# [ 97%]
29:syscfg-6.3.0-3465.14818.el7 ################################# [100%]一共29个包,包括了
omreport、syscfg、racadm7等命令。其中libsmbios、smbios-utils-bin可以通过yum进行安装。下载包的地址:https://linux.dell.com/repo/hardware/dsu/os_dependent/ ,还有一个方法下载包,下载omsa源,然后使用
yumdownloader的方法下载包。或者直接访问https://linux.dell.com/repo/hardware/latest/mirrors.cgi?osname=el7&basearch=x86_64&native=1会出现真实的下载地址。再次访问出现的URL就可以下载最新的OMSA的安装包了。el7表示centos7系统。
OMSA CLI常用命令
查看bmc以及bios设置的查看方法:
/opt/dell/srvadmin/sbin/srvadmin-services.sh start
/opt/dell/srvadmin/sbin/omreport chassis bmc
/opt/dell/srvadmin/sbin/omreport chassis bmc config=nic
/opt/dell/srvadmin/sbin/omreport chassis biossetup
其他相关命令可以使用/opt/dell/srvadmin/sbin/omreport -?来获取命令帮助。其他命令可以参考戴尔服务器使用omreport(OMSA)查看监控硬件信息
查询性能模式:
[root@localhost ~]# /opt/dell/srvadmin/sbin/omreport chassis biossetup |sed -n '/System Profile Settings/,/System Security/p'
System Profile Settings
------------------------------------------
System Profile : Performance
CPU Power Management : Maximum Performance
Memory Frequency : Maximum Performance
Turbo Boost : Enabled
C1E : Disabled
C States : Disabled
Monitor/Mwait : Enabled
Memory Patrol Scrub : Standard
Memory Refresh Rate : 1x
Memory Operating Voltage : Auto
Collaborative CPU Performance Control : Disabled
racadm也是可以获取到这个信息:
[root@localhost ~]# /opt/dell/srvadmin/bin/idracadm7 get BIOS.SysProfileSettings
[Key=BIOS.Setup.1-1#SysProfileSettings]
MemFrequency=MaxPerf
MemPatrolScrub=Standard
MemRefreshRate=1x
ProcC1E=Disabled
ProcCStates=Disabled
ProcPwrPerf=MaxPerf
ProcTurboMode=Enabled
SysProfile=PerfOptimized
syscfg也是可以:
[root@localhost ~]# /opt/dell/toolkit/bin/syscfg --ProcPwrPerf
ProcPwrPerf=maxperf
[root@localhost ~]# /opt/dell/toolkit/bin/syscfg --SysProfile
SysProfile=perfoptimized
参考:
DELL OpenManage Server Administrator安装及使用
mysql 日志为utc时间
设置为系统时间:
-
通过配置文件
[mysqld]
log_timestamps=SYSTEM -
在线设置
set global log_timestamps=SYSTEM;
查看当前配置
show global variables like 'log_timestamps';
kvm嵌套虚拟化
虚拟机cpu模式必须为 host-modle 或 host-passthrough
# 查看是否启用
cat /sys/module/kvm_intel/parameters/nested
# 添加启用配置
vi /etc/modprobe.d/kvm-nested.conf
options kvm-intel nested=1
options kvm-intel enable_shadow_vmcs=1
options kvm-intel enable_apicv=1
options kvm-intel ept=1
# 重载模块
modprobe -r kvm_intel
modprobe -a kvm_intel
run django脚本
#!/bin/bash
project_name='ds_backend'
pid_path="$project_name.pid"
logs_path='logs'
source venv/bin/activate
stop(){
[ -f $pid_path ] && pid=`cat $pid_path` && [ `ps -ef|grep $pid|grep -v grep|wc -l` -gt 0 ] && kill $pid || echo "$project_name not runing"
}
start(){
[ ! -d $logs_path ] && mkdir $logs_path
gunicorn -p $pid_path --log-file $logs_path/$project_name.log --access-logfile '-' --capture-output -D $project_name.wsgi
}
status(){
[ -f $pid_path ] && pid=`cat $pid_path` && [ `ps -ef|grep $pid|grep -v grep|wc -l` -gt 0 ] && echo "$project_name is runing: $pid" || echo "$project_name not runing"
}
restart(){
[ -f $pid_path ] && pid=`cat $pid_path` && [ `ps -ef|grep $pid|grep -v grep|wc -l` -gt 0 ] && kill $pid
start
}
case $1 in
start) restart;;
stop) stop;;
status) status;;
restart) restart;;
*)
echo 'Usage: sh $0 {start|stop|status|restart}'
;;
esac
nginx静态资源配置
server {
# 图片、视频
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|flv|mp4|ico)$ {
expires 30d;
access_log off;
}
# 字体
location ~ .*\.(eot|ttf|otf|woff|svg)$ {
expires 30d;
access_log off;
}
# js、css
location ~ .*\.(js|css)?$ {
expires 7d;
access_log off;
}
}
zabbix 微信脚本
#!/bin/bash
#https://work.weixin.qq.com/api/doc/90000/90135/90236#%E6%96%87%E6%9C%AC%E6%B6%88%E6%81%AF
CorpID='wxe464964f5ce6d80d'
Secret='NUJkJytNlone5r0qDUT6Rua082yePex4uO1vazLd-UA'
GURL="https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid=$CorpID&corpsecret=$Secret"
Gtoken=$(/usr/bin/curl -s -G $GURL | awk -F\" '{print $10}')
PURL="https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token=$Gtoken"
/usr/bin/curl --data-ascii "$(cat <<EOF
{
"touser": "${1//,/|}",
"toparty": "2",
"msgtype": "text",
"agentid": 1,
"text": {"content": "$2\n\n${3//\"/}"}
}
EOF
)" $PURL
jenkins pipeline
pipeline {
agent {
// 执行节点
node {
label 'master'
}
}
// 定义环境变量
environment {
// 您 Docker Hub 仓库的地址
REGISTRY = 'docker.io'
// 您的 Docker Hub 用户名
DOCKERHUB_USERNAME = 'yyxx'
// Docker 镜像名称
APP_NAME = 'devops-go-sample'
// 使用credentials 获取KubeSphere创建的凭证, docker 是您在 KubeSphere 用 Docker Hub 访问令牌创建的凭证 ID
DOCKERHUB_CREDENTIAL = credentials('docker')
// 您在 KubeSphere 创建的 kubeconfig 凭证 ID
KUBECONFIG_CREDENTIAL_ID = 'kubeconfig'
// 您在 KubeSphere 创建的项目名称,不是 DevOps 工程名称
PROJECT_NAME = 'ops'
}
// 重试3次
options { retry(3) }
stages {
// 步骤1
stage('docker login') {
steps{
sh 'echo $DOCKERHUB_CREDENTIAL_PSW | docker login -u $DOCKERHUB_CREDENTIAL_USR --password-stdin'
}
}
// 步骤2
stage('build & push') {
steps {
sh 'git clone https://github.com/GavinTan/devops-go-sample.git'
sh 'cd devops-go-sample && docker build -t $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME .'
sh 'docker push $REGISTRY/$DOCKERHUB_USERNAME/$APP_NAME'
}
}
}
post {
// 失败后执行
failure {
echo '123'
sh 'rm -rf devops-go-sample'
}
}
}
终端字体
添加字体到/usr/share/fonts
生成字体索引缓存
mkfontscale && mkfontdir && fc-cache
django导入默认数据
JSON:
[
{
"model": "myapp.person",
"pk": 1,
"fields": {
"first_name": "John",
"last_name": "Lennon"
}
},
{
"model": "myapp.person",
"pk": 2,
"fields": {
"first_name": "Paul",
"last_name": "McCartney"
}
}
]
YAML:
- model: myapp.person
pk: 1
fields:
first_name: John
last_name: Lennon
- model: myapp.person
pk: 2
fields:
first_name: Paul
last_name: McCartney
导入数据:
python manage.py loaddata data.json
参考:https://docs.djangoproject.com/zh-hans/3.2/howto/initial-data/
mysql查看数据库占用大小
查出所有的数据库的占用空间是多少MB
select
table_schema as '数据库',
sum(table_rows) as '记录数',
sum(truncate(data_length/1024/1024, 2)) as '数据容量(MB)',
sum(truncate(index_length/1024/1024, 2)) as '索引容量(MB)'from information_schema.tables
group by table_schema
order by sum(data_length) desc, sum(index_length) desc;
查看所有的数据库以及该数据库下各个表的占用的空间是多少MB以及各个表的记录数
select
table_schema as '数据库',
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)'from information_schema.tables
order by data_length desc, index_length desc;
查看某个数据库的记录数以及占用的空间是多少MB
select
table_schema as '数据库',
sum(table_rows) as '记录数',
sum(truncate(data_length/1024/1024, 2)) as '数据容量(MB)',
sum(truncate(index_length/1024/1024, 2)) as '索引容量(MB)'from information_schema.tables
where table_schema='mysql';
查看某个数据库的各个表占用的空间是多少MB
select
table_schema as '数据库',
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)'from information_schema.tables
where table_schema='mysql'order by data_length desc, index_length desc;
sendmail发送邮件
#!/bin/bash
SMTP_server='smtp.163.com' # SMTP服务器
username='good_zabbix@163.com' # 用户名
password='URMAXCTGAXGLFIVQ' # 密码
from_email_address='good_zabbix@163.com' # 发件人Email地址
to_email_address="$1" # 收件人Email地址,zabbix传入的第一个参数
message_subject_utf8="$2" # 邮件标题,zabbix传入的第二个参数
message_body_utf8="$3" # 邮件内容,zabbix传入的第三个参数
# 转换邮件标题为GB2312,解决邮件标题含有中文,收到邮件显示乱码的问题。
message_subject_gb2312=`iconv -t GB2312 -f UTF-8 << EOF
$message_subject_utf8
EOF`
[ $? -eq 0 ] && message_subject="$message_subject_gb2312" || message_subject="$message_subject_utf8"
# 转换邮件内容为GB2312
message_body_gb2312=`iconv -t GB2312 -f UTF-8 << EOF
$message_body_utf8
EOF`
[ $? -eq 0 ] && message_body="$message_body_gb2312" || message_body="$message_body_utf8"
# 发送邮件
sendEmail='/usr/local/sendEmail/sendEmail'
$sendEmail -s "$SMTP_server" -xu "$username" -xp "$password" -f "$from_email_address" -t "$to_email_address" -u "$message_subject" -m "$message_body" -o message-content-type=text -o message-charset=gb2312 -o tls=no
生成随机密码
tr -dc \~\`\!@#\$\%\^\&\*\(\)\-\_\+\=\|\\\?\/\.\>\,\<A-Za-z0-9_ < /dev/urandom|head -c *|xargs
pwgen * 1
mkpasswd -l *
openssl rand -base64 *
*为多少位数
django重建表
删除数据库所有表以及app目录下migrations文件夹,重新执行下面命令
python manage.py makemigrations --empt appname
python manage.py makemigrations
python manage.py migrate
tlbb
https://github.com/yulinzhihou/gstlenv
https://gitee.com/zhao-kai135/one-key
https://github.com/liuguangw/billing_go
es修改日志按天数保留
# 默认是按大小2GB
# appender.rolling.strategy.action.condition.nested_condition.type = IfAccumulatedFileSize
# appender.rolling.strategy.action.condition.nested_condition.exceeds = 2GB
appender.rolling.strategy.action.condition.nested_condition.type = IfLastModified
appender.rolling.strategy.action.condition.nested_condition.age = 7D
清理cache占用大量内存
total used free shared buff/cache available
Mem: 125Gi 999Mi 120Gi 4.0Gi 4.2Gi 119Gi
Swap: 8.0Gi 3.0Mi 8.0Gi
available表示应用程序还可以申请到的内存
首先了解下两个概念buff和cache
- buff(Buffer Cache)是一种I/O缓存,用于内存和硬盘的缓冲,是io设备的读写缓冲区。根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
- cache(Page Cache)是一种高速缓存,用于CPU和内存之间的缓冲 ,是文件系统的cache。把读取过的数据保存起来,重新读取时若命中(找到需要的数据)就不要去读硬盘了,若没有命中就读硬盘。其中的数据会根据读取频率进行组织,把最频繁读取的内容放在最容易找到的位置,把不再读的内容不断往后排,直至从中删除。
它们都是占用内存。两者都是RAM中的数据。简单来说,buff是即将要被写入磁盘的,而cache是被从磁盘中读出来的。
目前进程正在实际被使用的内存的计算方式为used-buff/cache,通过释放buff/cache内存后,我们还可以使用的内存量free+buff/cache。通常我们在频繁存取文件后,会导致buff/cache的占用量增高。
Linux默认使用的是lazy模式,即内存如果还够用,则不会主动释放当前的占用的buffer和cache,如果需要内存,则会自动释放buffer和cache,所以正常情况下,cache占用高不会对系统造成影响。
手动清除:
sync;sync;sync
echo 3 > /proc/sys/vm/drop_caches
- sync:将所有未写的系统缓冲区写到磁盘中,包含已修改的i-node、已延迟的块I/O和读写映射文件
- echo 1 > /proc/sys/vm/drop_caches:清除page cache
- echo 2 > /proc/sys/vm/drop_caches:清除回收slab分配器中的对象(包括目录项缓存和inode缓存)。slab分配器是内核中管理内存的一种机制,其中很多缓存数据实现都是用的pagecache。
- echo 3 > /proc/sys/vm/drop_caches:清除pagecache和slab分配器中的缓存对象。/proc/sys/vm/drop_caches的值,默认为0
定时清除脚本:
#!/bin/bash
#每两小时清除一次缓存
echo "开始清除缓存"
sync;sync;sync #写入硬盘,防止数据丢失
sleep 10 #延迟10秒
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
nfs
安装:
yum -y install nfs-utils
配置文件:
/data/nfs-data 172.16.7.0/24(rw,sync,no_root_squash)
启动:
systemctl enable rpcbind
systemctl enable nfs
systemctl start rpcbind
systemctl start nfs
firewall-cmd --zone=public --permanent --add-service={rpc-bind,mountd,nfs}success
firewall-cmd --reload
常用:
# 重新加载/etc/exports
exportfs -r
# 查看nfs服务器目录列表
showmount -e 172.16.7.14
# 挂载
mount -t nfs 172.16.7.14:/data/nfs-data /data/test
配置参数:
- 172.16.7.0/24: 访问网段限制;
- ro:共享目录只读;
- rw:共享目录可读可写;
- all_squash:所有访问用户都映射为匿名用户或用户组;
- no_all_squash(默认):访问用户先与本机用户匹配,匹配失败后再映射为匿名用户或用户组;
- root_squash(默认):将来访的root用户映射为匿名用户或用户组;
- no_root_squash:来访的root用户保持root帐号权限;
- anonuid=UID:指定匿名访问用户的本地用户UID,默认为nfsnobody(65534);
- anongid=GID:指定匿名访问用户的本地用户组GID,默认为nfsnobody(65534);
- secure(默认):限制客户端只能从小于1024的tcp/ip端口连接服务器;
- insecure:允许客户端从大于1024的tcp/ip端口连接服务器;
- sync:将数据同步写入内存缓冲区与磁盘中,效率低,但可以保证数据的一致性;
- async:将数据先保存在内存缓冲区中,必要时才写入磁盘;
- wdelay(默认):检查是否有相关的写操作,如果有则将这些写操作一起执行,这样可以提高效率;
- no_wdelay:若有写操作则立即执行,应与sync配合使用;
- subtree_check(默认) :若输出目录是一个子目录,则nfs服务器将检查其父目录的权限;
- no_subtree_check :即使输出目录是一个子目录,nfs服务器也不检查其父目录的权限,这样可以提高效率;
参考:https://segmentfault.com/a/1190000008629932
systemd 模板
cat << EOF > /etc/systemd/system/sshd.service
[Unit]
Description=OpenSSH server daemon
Documentation=man:sshd(8) man:sshd_config(5)
After=network.target sshd-keygen.service
Wants=sshd-keygen.service
[Service]
EnvironmentFile=/etc/sysconfig/sshd
ExecStart=/usr/sbin/sshd -D $OPTIONS
ExecReload=/bin/kill -HUP $MAINPID
Type=simple
KillMode=process
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target
EOF
cat << EOF > /etc/systemd/system/elasticsearch_exporter.service
[Unit]
Description=Prometheus elasticsearch_exporter
After=local-fs.target network-online.target network.target
Wants=local-fs.target network-online.target network.target
[Service]
User=root
Nice=10
ExecStart = /usr/local/bin/elasticsearch_exporter -es.all -es.indices -es.timeout 20s
ExecStop= /usr/bin/killall elasticsearch_exporter
[Install]
WantedBy=default.target
EOF
git 初始化提交
#初始化目录
git init
#添加提交的文件目录
git add .
#打tag标签init
git tag init
#本地提交
git commit -m "first commit"
#添加仓库
git remote add origin https://github.com/GavinTan/w-backend.git
#提交master分支
git push --set-upstream origin master init
zabbix启动中文
修改文件内容,将zh_cn后面的false改成true
vi /var/www/html/zabbix/include/locales.inc.php
拷贝字体置/var/www/html/zabbix/fonts/
修改配置文件
sed -i 's/DejaVuSans/simkai/g' /var/www/html/zabbix/include/defines.inc.php
centos7升级内核
#安装elrepo repo
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
#安装新内核
yum --enablerepo=elrepo-kernel install -y kernel-ml.x86_64
#安装新内核相关软件
yum --disablerepo=* --enablerepo=elrepo-kernel install -y kernel-ml-devel kernel-ml-tools kernel-ml-tools-libs kernel-ml-tools-libs-devel kernel-ml-headers
#查看所有内核
awk -F \' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg
#查看默认内核
grub2-editenv list
#将新内核设为默认grbu启动项
grub2-set-default 0
#生成 grub 配置文件
grub2-mkconfig -o /etc/grub2.cfg
参考:http://elrepo.org/tiki/HomePage
smokeping
图表说明:
- X轴表示时间,Y轴表示Ping请求时长
- 网络丢包和延迟不同的颜色和阴影表示,阴影块越大说明波动越大
- 图表中曲线上不同颜色表示丢包数、延迟不同,点击图表并选中范围可以放大
参数说明:
- med RTT:av md 平均中位数、av ls 平均损失、av sd 每轮中多次测量的平均标准偏差、am/as 平均中位数和平均标准差的比率
- median rtt:avg 平均值、max 最大值、min 最小值、now 当前中位数、sd 中位数的标准差、am 平均中位数与标准差的比率
- packet loss:avg 平均值、max 最大值、min 最小值、now 当前丢包率
- loss color:丢包颜色表示 0表示不丢包 1/20表示丢一个包
- probe:发送的探针数据包
jdbc
MySQL 8.0 开始数据库相比常用的 5.X 版本发生了比较大的变化,我们在连接数据库的过程中许多地方也要发生一些变化。
总结一下,想要利用 mysql-connector-java 与 MySQL 8.X 版本建立连接,有以下四个方面与 MySQL 5.X 版本相比发生了变化。
-
MySQL 8.0 以上版本驱动包版本 mysql-connector-java-8.X.jar
MySQL 版本和 mysql-connector-java 版本对应关系如下,MySQL官方也是推荐使用 mysql-connector-java-8.X.jar 去连接 MySQL 8.0 的版本
Connector/J version Driver Type JDBC version MySQL Server version Status 5.1 4 3.0, 4.0, 4.1, 4.2 5.6*, 5.7*, 8.0* General availability 8.0 4 4.2 5.6, 5.7, 8.0 General availability. Recommended version -
com.mysql.jdbc.Driver 更换为 com.mysql.cj.jdbc.Driver。
-
MySQL 8.0 以上版本不需要建立 SSL 连接的,需要显式关闭。
MySQL 5.7 之前版本,安全性做的并不够好,比如安装时生成的root空密码账号、存在任何用户都能连接上的 test 库等,导致数据库存在较大的安全隐患。从5.7版本开始MySQL官方对这些问题逐步进行了修复,到了 MySQL 8.0 以上版本已经不需要使用 SSL 进行连接加密了。但是高版本仍然保留了这个接口,所以需要在连接的时候手动写明是否需要进行 SSL 连接,这里我们手动关闭 SSL 连接加密就OK。
useSSL=false
-
最后还需要设置 CST。也就是设置时区。
serverTimezone=UTC
Class.forName("com.mysql.cj.jdbc.Driver");
conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/test_demo?useSSL=false&serverTimezone=UTC","root","password");
yum源
阿里源:
https://developer.aliyun.com/mirror/centos https://developer.aliyun.com/mirror/epel
centos6 Vault yum源:
#替换为官方Vault源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://static.lty.fun/%E5%85%B6%E4%BB%96%E8%B5%84%E6%BA%90/SourcesList/Centos-6-Vault-Official.repo
#替换为阿里云Vault镜像
wget -O /etc/yum.repos.d/CentOS-Base.repo https://static.lty.fun/%E5%85%B6%E4%BB%96%E8%B5%84%E6%BA%90/SourcesList/Centos-6-Vault-Aliyun.repo
Linux生成随机数
head -c 32 /dev/random | base64
openssl rand -hex 32
Python 简单http服务与ftp服务
http服务:
pip install SimpleHTTPAuthServer
#当前所在的文件夹设置为默认的Web目录启动http服务器,不接端口默认8000
#如果当前文件夹有index.html文件,会默认显示该文件;否则,会以文件列表的形式显示目录下所有文件.
python -m SimpleHTTPServer 80
#带验证的http服务
python -m SimpleHTTPAuthServer 88 ops:ops.ops123
#python3
python -m http.server 80
ftp服务:
pip install pyftpdlib
#当前所在的文件夹设置为默认的ftp目录启动ftp服务器,不接端口默认随机一个端口
python -m pyftpdlib -p 21
红帽cockpit web管理服务器
多服务器管理
yum install -y cockpit-dashboard
磁盘管理
yum install -y cockpit-storaged
docker管理
yum install -y cockpit-docker
kvm管理
yum install -y cockpit-machines
linux 设置时区
export TZ=Asia/Shanghai
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
weedfs mount
错误:mount: fusermount: exec: "fusermount": executable file not found in $PATH
yum install fuse
挂载后删除不了执行下面命令
fusermount -uz /data
获取Linux cpu核数
echo $(nproc)
生成 100w 记录的数据文件导入mysql
生成数据文件:
python -c "for i in range(1, 1+1000000): print(i)" > /tmp/base.txt
导入mysql:
use mydb
CREATE TABLE tmp_table ( id INT, PRIMARY KEY (id) );
load data local infile '/tmp/base.txt' replace into table tmp_table;
docker安装及相关设置
安装最新版(17.04 及以后的版本):
#脚本安装
export CHANNEL=stable
curl -fsSL https://get.docker.com/ | sh -s -- --mirror Aliyun
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
#yum安装
yum -y install yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum -y install docker-ce
CentOS 7 配置加速器:
在文件中找到 ExecStart= 这一行,并且在其行尾添加上registry-mirror
ExecStart=/usr/bin/dockerd --registry-mirror=https://registry.docker-cn.com
keepalived配置双机热备
Master 配置:
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_nginx {
script "[ `netstat -tnulp|grep 80|wc -l` -eq 0 ] && exit 1 || exit 0"
interval 2
weight -50
fall 3
user root
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.7
}
track_script {
chk_nginx
}
}
Backup 配置:
! Configuration File for keepalived
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_nginx {
script "[ `netstat -tnulp|grep 80|wc -l` -eq 0 ] && exit 1 || exit 0"
interval 2
weight -50
fall 3
user root
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.7
}
track_script {
chk_nginx
}
}
内网穿透
1.自带随机外网域名
2.frpc需要一台外网服务器
https://github.com/fatedier/frp/releases
生成mipsel架构clash解决Illegal instruction错误
#go 安装路径
export GOROOT=/usr/local/go/
#生成路径
export GOPATH=/root/go
export GOOS=linux
export GOARCH=mipsle
export GOMIPS=softfloat
go get -u -v github.com/Dreamacro/clash
openwrt
修改lan ip:
ssh 192.168.1.1
uci set network.lan.ipaddr=192.168.199.1
uci commit network
ifup lan
替换opkg源:
opkg源:
- 中国科技大学教育网官方主镜像网站:http://mirrors.ustc.edu.cn/OpenWrt
- 源教育网高速镜像站点:http://openwrt.proxy.ustclug.org/
- 清华大学开源软件镜像站:https://mirrors.tuna.tsinghua.edu.cn/
#替换
sed -i 's/downloads.openwrt.org/mirrors.tuna.tsinghua.edu.cn\/lede/g' /etc/opkg/distfeeds.conf
#还原
sed -i 's/mirrors.tuna.tsinghua.edu.cn\/lede/downloads.openwrt.org/g' /etc/opkg/distfeeds.conf
管理界面中文包:
opkg update
opkg install luci-i18n-base-zh-cn
wget https支持:
opkg update
opkg install wget ca-certificates openssl-util ca-bundle
安装sftp:
opkg update
opkg install openssh-sftp-server
#如果你想用Bonjour/Zeroconf在网络上公布服务,让Cyberduck找到它,你可以安装公布包
opkg install announce
/etc/init.d/announce enable
/etc/init.d/announce start
挂载sd /overlay:
#opkg install block-mount kmod-fs-ext4 kmod-usb-storage-extras
opkg install kmod-sdhci kmod-sdhci-mt7620 block-mount kmod-fs-ext4 e2fsprogs fdisk
#fdisk -l
block info
mkfs.ext4 /dev/mmcblk0
mount /dev/mmcblk0 /mnt
tar -C /overlay -cvf - . | tar -C /mnt -xf -
umount /mnt
block detect > /etc/config/fstab
config 'global'
option anon_swap '0'
option anon_mount '0'
option auto_swap '1'
option auto_mount '1'
option delay_root '5'
option check_fs '0'
config 'mount'
option target '/overlay' # 挂着路径
option uuid 'f2e07f24-88e4-47a6-8635-84e6a1da2953'
option enabled '1' # 启用
创建swap:
#创建要作为swap分区的文件
dd if=/dev/zero of=/root/swapfile bs=1G count=5
#格式化为交换分区文件
mkswap /root/swapfile
#启用swap
swapon /root/swapfile
#关闭swap
swapoff
config swap
option device /root/swapfile
option enabled 1
命令行json格式化输出
curl http://www.example.com | python -m json.tool
echo '{"action": "update_db", "data": {"project": "dalmatian", "env": "test","sqlfile_list": ["t3.sql"]}}' | python -m json.tool
docker添加中文支持
# docker-compose.yml
version: '3.3'
services:
lam:
build: .
#image: ldapaccountmanager/lam:stable
ports:
- "8088:80"
restart: always
# environment:
# LC_ALL: "en_US.UTF-8"
# LANG: "en_US.UTF-8"
# LANGUAGE: "en_US.UTF-8"
# Dockerfile - debian
FROM ldapaccountmanager/lam:stable
RUN apt-get update
RUN apt-get install -y locales locales-all
ENV LC_ALL zh_CN.utf8
ENV LANG zh_CN.utf8
ENV LANGUAGE zh_CN.utf8
git撤销commit到未提交状态
如何把最后一次commit撤销回Changes not staged和Untracked files区呢?
有3种情况:
-
把最后的commit切回Changes to be committed状态,使用命令:
git reset --soft HEAD^ -
把最后的commit切回Changes not staged for commit状态,使用命令:
git reset HEAD^ -
把Changes to be committed状态切回Changes not staged for commit状态,使用命令:
git reset HEAD <file>... # 单个文件
git reset HEAD -- . # 所有Changes to be committed的文件
参考:https://www.awaimai.com/2383.html
git上传可执行文件
# Stage the script.sh file
git add script.sh
# Flag it as executable
git update-index --chmod=+x script.sh
# Commit the change
git commit -m "Make script.sh executable."
# Push the commit
git push
python命令行不能使用方向键
apt install libreadline-dev
apt install libncurses-dev
编译python之前安装上面两个包
nginx配置websocket
location / {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
proxy_read_timeout 60s; # 默认情况下,如果代理服务器在60秒内未传输任何数据,则将关闭连接,可修改此参数增加超时时间
安装twisted模块
python3 -m pip install git+git://github.com/twisted/twisted.git
删除git上指定目录
#将远程仓库里面的项目拉下来
git pull origin master
#删除target文件夹
git rm -r --cached target
#提交
git commit -m '删除了target'
#将本次更改更新到git上去
git push -u origin master
本地项目中的target文件夹不收操作影响,删除的只是远程仓库中的target
进入目录自动载入 Python 虚拟环境配置
using git:
git clone https://github.com/kennethreitz/autoenv.git
echo 'source /opt/autoenv/activate.sh' >> ~/.bashrc
source ~/.bashrc
using pip:
pip install autoenv
echo "source `which activate.sh`" >> ~/.bashrc
source ~/.bashrc
配置目录下.env文件:
echo "source /opt/py3/bin/activate" > /opt/jumpserver/.env
生成ssh密钥
ssh-keygen -t rsa
tutum
mba811/tutum-hello-world
mongodb数据迁移
导出数据:
mongodump -h ip:port -u testUser -p testPwd -d testDB -o /tmp/mongodb/test.dump
导入数据:
mongorestore -u testUser -p testPwd -d testDB /tmp/mongodb/test.dump/testDB
percona-server-5.7 安装
编译安装:
#安装所需组件
yum install -y zlib-devel readline-devel ncurses-devel gcc-c++ gcc git libaio-devel cmake
#编译
tar zxf percona-server-5.7.21-20.tar.gz
cd percona-server-5.7.21-20
cmake . -DCMAKE_INSTALL_PREFIX=/usr/local/percona -DCMAKE_BUILD_TYPE=RelWithDebInfo -DBUILD_CONFIG=mysql_release -DFEATURE_SET=community -DWITH_EMBEDDED_SERVER=OFF -DDOWNLOAD_BOOST=1 -DWITH_BOOST=.
make -j && make install
yum安装:
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-4/percona-release-0.1-4.noarch.rpm
yum install Percona-Server-server-57
初始化:
#获取默认临时密码
cat /var/log/mysqld.log | grep "A temporary password" | awk -F " " '{print$11}'
#修改安全策略密码复杂度
# 0 【长度】
# 1 【 长度;数字、小写/大写和特殊字符】 默认
# 2 【 长度;数字、小写/大写和特殊字符;字典文件】
mysql -uroot -p -e 'set global validate_password_policy=0;'
#安全配置向导
mysql_secure_installation
find使用
find获取文件名:
find /root -name *.jpg -printf "%f\n"
查找包含指定内容的文件:
find . -type f -exec grep -l "Hello World" {} \;
#grep -Ilr "Hello World" ./
查找指定时间范围内的文件:
find -name *.java -newermt '2015-12-25 08:00:00' ! -newermt '2015-12-25 21:00:00'
#ls -alR --full-time * | grep "2015-12-25"| grep ".java"
zabbix执行远程命令
客户端配置文件添加配置:
EnableRemoteCommands=1 #启用远程命令
LogRemoteCommands=1 #启用远程命令日志
配置sudo权限:
visudo
#授权zabbix用户使用sudo
zabbix ALL=(ALL) NOPASSWD: /usr/bin/systemctl restart myservice
#如果存在Defaults requiretty配置存在需要配置zabbix用户或者组不需要终端
Defaults:zabbix !requiretty #zabbix用户不需要终端
Defaults:%zabbix !requiretty #zabbix组不需要终端
LVM卷组
创建
#创建物理卷
pvcreate /dev/sdb
#创建逻辑卷组
vgcreate volGroup00 /dev/sdb
#创建逻辑卷剩下所有空间都给逻辑卷
lvcreate -l +100%FREE -n LogVol01 volGroup00
#创建逻辑卷(356为Total PE 数)
lvcreate -l 356 -n LogVol01 volGroup00
扩容
#创建物理卷
pvcreate /dev/sdc
#添加物理卷进卷组
vgextend volGroup00 /dev/sdc
#扩展所有空间给逻辑卷
vextend -l +100%FREE -n LogVol01 volGroup00
#扩展指定10G空间给逻辑卷
vextend -L +10G /dev/volGroup00/LogVol01
重定义大小(df -h看不到空间变化)
#ext2 ext3 ext4文件系统使用
resize2fs -p /dev/volGroup00/LogVol01
#xfs文件系统使用
xfs_growfs /dev/volGroup00/LogVol01
缩容
#卸载
umount /dev/volGroup00/LogVol01
#检查
e2fsck -f /dev/volGroup00/LogVol01
#缩小文件系统为50g
resize2fs /dev/volGroup00/LogVol01 50g
#缩小lv容量为50g
lvreduce -L 50G /dev/volGroup00/LogVol01
删除
#删逻辑卷
lvremove /dev/volGroup00/LogVol01
#删卷组
vgremove volGroup00
#删物理卷
pvremove /dev/sdb
#清除无效的卷
vgreduce --removemissing --force volGroup00
挂载
mkfs.ext4 /dev/volGroup00/LogVol01
mount /dev/mapper/volGroup00-LogVol01 /data
vi /etc/fstab
/dev/mapper/volGroup00-LogVol01 /data ext4 defaults 1 2
- pvdisplay:显示物理卷信息
- vgdisplay:显示卷组信息
- lvdisplay:显示逻辑卷信息
vsftp 出现报错530 Login incorrect
#使用下面命令查看pam库是否有加载
ldd /usr/local/sbin/vsftpd|grep pam
#未加载安装pam后重新再编译vsftp安装
yum install pam-devel
yum删除重复软件包
#列出重复的包
package-cleanup --dupes
#删除重复的包
package-cleanup --cleandupes
yum下载rpm包
yum install --downloadonly --downloaddir=/tmp <package-name>
linux scoket5代理转换http代理
安装:
wget https://www.irif.fr/~jch/software/files/polipo/polipo-1.1.1.tar.gz
tar zxf polipo-1.1.1.tar.gz
cd polipo-1.1.1
yum install -y texinfo
make all && make install
cp config.sample /etc/texinfo.conf
vi /etc/texinfo.conf
socksParentProxy = "192.168.120.110:10000"
socksProxyType = socks5
启动:
polipo -c /etc/texinfo.conf
设置http代理:
export http_proxy=127.0.0.1:8123
linux 连接vpn(pptp)
安装:
yum install ppp pptp pptp-setup
创建VPN连接:
modprobe ppp_mppe
pptpsetup --create vpn名称 --server ip地址 --username 账号 --password 密码 --start
连接VPN连接:
pppd call vpn名称
添加路由:
route add -net 192.168.200.0/24 dev ppp0
断开vpn连接:
/etc/init.d/network restart
VPN开启关闭脚本:
cp /usr/share/doc/ppp-2.4.5/scripts/pon /usr/sbin/
cp /usr/share/doc/ppp-2.4.5/scripts/poff /usr/sbin/
chmod +x /usr/sbin/pon
chmod +x /usr/sbin/poff
poff test #关闭vpn
pon test #开启vpn
错误:
Using interface ppp0Connect: ppp0 <--> /dev/pts/3CHAP authentication succeededLCP terminated by peer (MPPE required but peer refused)Modem hangup
解决方法:
# test为创建的vpn名称
echo 'require-mppe-128' >> /etc/ppp/peers/test
错误(CentOS7):
LCP: timeout sending Config-RequestsConnection terminated.Modem hangup
解决方法:
modprobe nf_conntrack_pptp
modprobe nf_conntrack_proto_gre
nginx http强制跳转https
return 301 https://$server_name$request_uri;
shadowsocks安装
1.安装
https://github.com/shadowsocks/shadowsocks-libev
2.bbr加速脚本
wget --no-check-certificate https://github.com/teddysun/across/raw/master/bbr.sh && chmod +x bbr.sh && ./bbr.sh
安装完成后,脚本会提示需要重启 VPS,输入 y 并回车后重启。重启完成后,进入 VPS,验证一下是否成功安装最新内核并开启 TCP BBR,输入以下命令:
查看内核版本,含有 4.13 就表示 OK 了
uname -r
查看返回值是否为 net.ipv4.tcp_available_congestion_control = bbr cubic reno
sysctl net.ipv4.tcp_available_congestion_control
查看返回值是否为 net.ipv4.tcp_congestion_control = bbr
sysctl net.ipv4.tcp_congestion_control
查看返回值是否为 net.core.default_qdisc = fq
sysctl net.core.default_qdisc
返回值有 tcp_bbr 模块即说明 bbr 已启动。注意:并不是所有的 VPS 都会有此返回值,若没有也属正常。
lsmod | grep bbr
参考链接:https://teddysun.com/489.html
3.混淆插件simple-obfs
https://github.com/shadowsocks/simple-obfs
linux 大于2TB磁盘创建
用part命令对3T硬盘进行分区
parted /dev/sdb
mklabel gpt #用gpt格式可以将3TB弄在一个分区里
unit TB #设置单位为TB
mkpart primary 0 3 #设置为一个主分区,大小为3TB,开始是0,结束是3
print #显示设置的分区大小
quit #退出parted程序
格式化
mkfs.xfs /dev/sdb1
网站压力测试
对baidu进行,1000次请求,并发用户10的压力测试
ab -n 1000 -c 10 http://www.baidu.com
vi 去空格
- 删除空格行:非编辑状态下输入 :g/^$/d
- 删除行首空格:非编辑状态下输入: %s/^\s*//g
- 删除行尾空格:非编辑状态下输入: %s/\s*$//g
查看文件权限
stat -c %a test.txt
常用的参数:
- %a Access rights in octal 8进制显示访问权限,0644
- %A Access rights in human readable form 以人类可读的形式输出,
- %F File type 文件的类型
- %g Group ID of owner 所属组gid的号码
- %G Group name of owner 所属组的名称
- %h Number of hard links 硬连接的数量
- %i Inode number inode的值
- %n File name 文件名
- %o I/O block size IO块大小
- %s Total size, in bytes 文件的总大小,字节显示;
- %u User ID of owner 所属主的uid号码
- %U User name of owner 所属主的名称
- %x Time of last access 最后访问的时间
- %X Time of last access as seconds since Epoch 最后访问时间的时间戳
- %y Time of last modification 最后修改的时间
- %Y Time of last modification as seconds since Epoch 最后修改时间的时间戳
- %z Time of last change 最后更改的时间
- %Z Time of last change as seconds since Epoch 最后更改的时间的时间戳
shell 字符串变量值的替换
file=/dir1/dir2/dir3/my.file.txt
# 将第一个dir替换为path:/path1/dir2/dir3/my.file.txt
${file/dir/path}
#将全部的dir替换为path:/path1/path2/path3/my.file.txt
${file//dir/path}
$ 的一些功能:
${file#*/}:拿掉第一条 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt${file##*/}:拿掉最后一条 / 及其左边的字符串:my.file.txt${file#*.}:拿掉第一个 . 及其左边的字符串:file.txt${file##*.}:拿掉最后一个 . 及其左边的字符串:txt${file%/*}:拿掉最后条 / 及其右边的字符串:/dir1/dir2/dir3${file%%/*}:拿掉第一条 / 及其右边的字符串:(空值)${file%.*}:拿掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file${file%%.*}:拿掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my
说明:
- # 是去掉左边(在键盘上 # 在 $ 之左边)
- % 是去掉右边(在键盘上 % 在 $ 之右边)
- 单一个符号(# 或 %)是最小匹配,两个符号(# 或 %)是最大匹配
参考链接: http://wiki.jikexueyuan.com/project/13-questions-of-shell/eight.html
linux获取外网ip
curl -s http://geoiplookup.net/ |grep -b1 ISP |head -n1|awk -F ">" '{print $2}'|awk -F "<" '{print $1}'
curl my.tanwen.net/ip
locale 编码报错
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: Cannot set LC_ALL to default locale: No such file or directory
解决方法:
yum install glibc-common
http://blog.csdn.net/wave_1102/article/details/45116783
Windows下编辑的shell脚本在Linux无法执行
在windows下编辑的shell脚本放到Linux环境下比如手机中运行时就会出一些莫名其妙的错误,一些非常简单的shell命令也会报错。其实错误的原因只有一个就是格式问题,在windows下编辑出的shell脚本格式为dos格式,而linux只能执行格式为unix格式的脚本。因为在dos/window下按一次回车键实际上输入的是“回车(CR)”和“换行(LF)”,即'\r\n',而Linux/unix下按一次回车键只输入“换行(LF)”,即'\n',所以修改的sh文件在每行都会多了��一个CR,所以Linux下运行时就会报错找不到命令。
解决这个问题的方法有几种:
- 通过vi工具修改格式 在linux下通过vi打开该文件。在命令模式下使用set ff命令,可以看到该文件的格式为fileformat=dos cat -A filename 可以看到每行尾都用^M 然后修改文件格式:set ff=unix,最后保存退出就可以了。
- 用fromdos命令转换 fromdos命令是ubuntu下进行dos格式文件转换成linux系统可以使用的文件格式的命令。 windows下很大编辑器本身也可以支持linux格式的文件编辑保存,不过默认并不是linux格式的 最简单的办法就是
- 找一个已经是linux格式的shell脚本文件,在此基础上进行修改保存,这样保存之后仍然也是linux格式的。
- 使用dos2unix命令转换
pip 安装
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python get-pip.py
curl https://bootstrap.pypa.io/get-pip.py|python
脚本取得网站状态码
shell
curl -I -m 10 -o /dev/null -s -w %{http_code} www.baidu.com
python
import urllib
status=urllib.urlopen("http://www.baidu.com").code
print status
查找指定日期文件
要在一个目录中查找2015-12-25创建的Java文件
find -name *.java -newermt '2015-12-25 08:00:00' ! -newermt '2015-12-25 21:00:00'
ls -alR --full-time * | grep "2015-12-25"| grep ".java"
centos7 创建自定义服务
[Unit]
Description= ads rank web server
[Service]
Type=simple
ExecStart=/work/jbp_ads_server/jbp_ads_server
ExecReload=/bin/kill -HUP $MAINPID
KillMode=control-group
Restart=on-failure
RestartSec=3s
PrivateTmp=true
[Install]
WantedBy=multi-user.target
mv adsrankweb.service /usr/lib/systemd/system
systemctl daemon-reload
systemctl start adsrankweb
systemctl stop adsrankweb
screen 保存日志
echo 'logfile /tmp/screenlog_%t.log' >> /etc/screenrc
screen -L -t vod -S run
内存缓存
Cache,译作“缓存”,指 CPU 和内存之间高速缓存。
Buffer,译作“缓冲区”,指在写入磁盘前的存储再内存中的内容。在本文中,Buffer 和 Cache 有时候会通指。
#仅清除页面缓存(PageCache) 生产环境适用
sync; echo 1 > /proc/sys/vm/drop_caches #清除目录项和inodesync; echo 2 > /proc/sys/vm/drop_caches #清除页面缓存,目录项和inodesync; echo 3 > /proc/sys/vm/drop_caches
git 免密码
永久保存
git config --global credential.helper store
l临时,默认保存15分钟
git config --global credential.helper cache
或者修改config
vi .git/config
url = http://username:password@xiaohulu.hub520.com/yinzhonghua/xhl_newguild.git
linux l2tp 安装脚本
Ubuntu & Debian
wget https://git.io/vpnsetup
CentOS & RHEL
wget https://git.io/vpnsetup-centos
github: https://github.com/hwdsl2/setup-ipsec-vpn
linux 查找
- find #查找所有文件
- locate #跟find类似速度较快直接搜索 locatedb数据库
- which #通过环境变量查找
- whereis #搜索程序二进�制文件
linux 测试网速
wget https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py
python speedtest.py
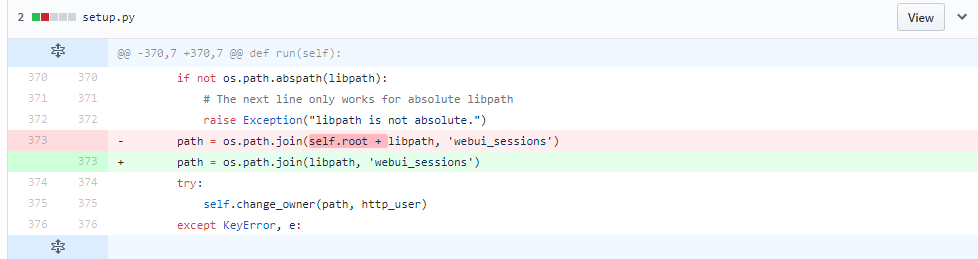
cobbler 安装错误
File "setup.py", line 373, in run path = os.path.join(self.root + libpath, 'webui_sessions')TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
linux文本处理命令
- sor
- tr
- cut
- paste
- uniq
- tee
升级php5.6
方法1:
rpm -Uvh http://mirror.webtatic.com/yum/el6/latest.rpm
yum install php56w php56w-opcache php56w-fpm php56w-mysql php56w-bcmath php56w-mbstring php56w-gd php56w-xmlwriter
方法2:
配置yum源
rpm -Uvh http://ftp.iij.ad.jp/pub/linux/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
rpm -Uvh http://rpms.famillecollet.com/enterprise/remi-release-6.rpm
以下是CentOS 7.0的源。
yum install epel-releaserpm -ivh http://rpms.famillecollet.com/enterprise/remi-release-7.rpm
使用yum list命令查看可安装的包(Packege)
yum list --enablerepo=remi --enablerepo=remi-php56 | grep php
安装PHP5.6.x
yum install --enablerepo=remi --enablerepo=remi-php56 php php-opcache php-devel php-mbstring php-mcrypt php-mysqlnd php-phpunit-PHPUnit php-pecl-xdebug php-pecl-xhprof
后台任务
& nohup screen #后台执行
jobs #查看后台任务
fg #将程序放在前台执行(切换后台任务到前台)
bg #将程序放在后台执行
saltstack安装
CentOS 6:
yum install https://repo.saltstack.com/yum/redhat/salt-repo-latest-1.el6.noarch.rpm
yum install salt-master salt-minion salt-ssh salt-syndic salt-cloud salt-api
service salt-minion restart
CentOS 7:
yum install https://repo.saltstack.com/yum/redhat/salt-repo-latest-1.el7.noarch.rpm
yum install salt-master salt-minion salt-ssh salt-syndic salt-cloud salt-api
systemctl restart salt-minion
Ubuntu安装桌面环境
sudo apt-get install xinit
sudo apt-get install gdm
sudo apt-get install ubuntu-desktop
Ubuntu提示W: mdadm: /etc/mdadm/mdadm.conf defines no arrays
mv /etc/mdadm/mdadm.conf /etc/mdadm/mdadm.conf.bak
update-initramfs -u
MySQL 5.6 my.cnf 参数说明
# 以下选项会被MySQL客户端应用读取。
# 注意只有MySQL附带的客户端应用程序保证可以读取这段内容。
# 如果你想你自己的MySQL应用程序获取这些值。
# 需要在MySQL客户端库初始化的时候指定这些选项。
#
[client]
#password = [your_password]
port = @MYSQL_TCP_PORT@
socket = @MYSQL_UNIX_ADDR@
# *** 应用定制选项 ***
#
# MySQL 服务端
#
[mysqld]
# 一般配置选项
port = @MYSQL_TCP_PORT@
socket = @MYSQL_UNIX_ADDR@
# back_log 是操作系统在监听队列中所能保持的连接数,
# 队列保存了在 MySQL 连接管理器线程处理之前的连接.
# 如果你有非常高的连接率并且出现 “connection refused” 报错,
# 你就应该增加此处的值.
# 检查你的操作系统文档来获取这个变量的最大值.
# 如果将back_log设定到比你操作系统限制更高的值,将会没有效果
back_log = 300
# 不在 TCP/IP 端口上进行监听.
# 如果所有的进程都是在同一台服务器连接到本地的 mysqld,
# 这样设置将是增强安全的方法
# 所有 mysqld 的连接都是通过 Unix Sockets 或者命名管道进行的.
# 注意在 Windows下如果没有打开命名管道选项而只是用此项
# (通过 “enable-named-pipe” 选项) 将会导致 MySQL 服务没有任何作用!
#skip-networking
# MySQL 服务所允许的同时会话数的上限
# 其中一个连接将被 SUPER 权限保留作为管理员登录.
# 即便已经达到了连接数的上限.
max_connections = 3000
# 每个客户端连接最大的错误允许数量,如果达到了此限制.
# 这个客户端将会被 MySQL 服务阻止直到执行了 “FLUSH HOSTS” 或者服务重启
# 非法的密码以及其他在链接时�的错误会增加此值.
# 查看 “Aborted_connects” 状态来获取全局计数器.
max_connect_errors = 50
# 所有线程所打开表的数量.
# 增加此值就增加了 mysqld 所需要的文件描述符的数量
# 这样你需要确认在 [mysqld_safe] 中 “open-files-limit” 变量设置打开文件数量允许至少等于 table_cache 的值
table_open_cache = 4096
# 允许外部文件级别的锁. 打开文件锁会对性能造成负面影响
# 所以只有在你在同样的文件上运行多个数据库实例时才使用此选项(注意仍会有其他约束!)
# 或者你在文件层面上使用了其他一些软件依赖来锁定 MyISAM 表
#external-locking
# 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的 BLOB 字段一起工作时相当必要)
# 每个连接独立的大小,大小动态增加
max_allowed_packet = 32M
# 在一个事务中 binlog 为了记录 SQL 状态所持有的 cache 大小
# 如果你经常使用大的,多声明的事务,你可以增加此值来获取更大的性能.
# 所有从事务来的状态都将被缓冲在 binlog 缓冲中然后在提交后一次性写入到 binlog 中
# 如果事务比此值大, 会使用磁盘上的临时文件来替代.
# 此缓冲在每个连接的事务第一次更新状态时被创建
binlog_cache_size = 4M
# 独立的内存表所允许的最大容量.
# 此选项为了防止意外创建一个超大的内存表导致永尽所有的内存资源.
max_heap_table_size = 128M
# 随机读取数据缓冲区使用内存(read_rnd_buffer_size):和顺序读取相对应,
# 当 MySQL 进行非顺序读取(随机读取)数据块的时候,会利用>这个缓冲区暂存读取的数据
# 如根据索引信息读取表数据,根据排序后的结果集与表进行 Join 等等
# 总的来说,就是当数据块的读取需要满足>一定的顺序的情况下,MySQL 就需要产生随机读取,进而使用到 read_rnd_buffer_size 参数所设置的内存缓冲区
read_rnd_buffer_size = 16M
# 排序缓冲被用来处理类似 ORDER BY 以及 GROUP BY 队列所引起的排序
# 如果排序后的数据无法放入排序缓冲,一个用来替代的基于磁盘的合并分类会被使用
# 查看 “Sort_merge_passes” 状态变量.
# 在排序发生时由每个线程分配
sort_buffer_size = 16M
# 此缓冲被使用来优化全联合(FULL JOINS 不带索引的联合).
# 类似的联合在极大多数情况下有非常糟糕的性能表现,但是将此值设大能够减轻性能影响.
# 通过 “Select_full_join” 状态变量查看全联合的数量
# 当全联合发生时,在每个线程中分配
join_buffer_size = 16M
# 我们在 cache 中保留多少线程用于重用
# 当一个客户端断开连接后,如果 cache 中的线程还少于 thread_cache_size,则客户端线程被放入cache 中.
# 这可以在你需要大量新连接的时候极大的减少线程创建的开销
# (一般来说如果你有好的线程模型的话,这不会有明显的性能提升.)
thread_cache_size = 16
# 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量.
# 此值只对于支持 thread_concurrency() 函数的系统有意义( 例如Sun Solaris).
# 你可可以尝试使用 [CPU数量]*(2..4) 来作为 thread_concurrency 的值
thread_concurrency = 8
# 查询缓冲常被用来缓冲 SELECT 的结果并且在下一次同样查询的时候不再执行直接返回结果.
# 打开查询缓冲可以极大的提高服务器速度, 如果你有大量的相同的查询并且很少修改表.
# 查看 “Qcache_lowmem_prunes” 状态变量来检查是否当前值对于你的负载来说是否足够高.
# 注意: 在你表经常变化的情况下或者如果你的查询原文每次都不同,
# 查询缓冲也许引起性能下降而不是性能提升.
query_cache_size = 128M
# 只有小于此设定值的结果才会被缓冲
# 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖.
query_cache_limit = 4M
# 被全文检索索引的最小的字长.
# 你也许希望减少它,如果你需要搜索更短字的时候.
# 注意在你修改此值之后,你需要重建你的 FULLTEXT 索引
ft_min_word_len = 8
# 如果你的系统支持 memlock() 函数,你也许希望打开此选项用以让运行中的 mysql 在在内存高度紧张的时候,数据在内存中保持锁定并且防止可能被 swapping out
# 此选项对于性能有益
#memlock
# 当创建新表时作为默认使用的表类型,
# 如果在创建表示没有特别执行表类型,将会使用此值
default_table_type = InnoDB
# 线程使用的堆大小. 此容量的内存在每次连接时被预留.
# MySQL 本身常不会需要超过 64K 的内存
# 如果你使用你自己的需要大量堆的 UDF 函数或者你的操作系统对于某些操作需要更多的堆,你也许需要将其设置的更高一点.
thread_stack = 512K
# 设定默认的事务隔离级别.可用的级别如下:
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE
transaction_isolation = REPEATABLE-READ
# 内部(内存中)临时表的最大大小
# 如果一个表增长到比此值更大,将会自动转换为基于磁盘的表.
# 此限制是针对单个表的,而不是总和.
tmp_table_size = 128M
# 打开二进制日志功能.
# 在复制(replication)配置中,作为 MASTER 主服务器必须打开此项
# 如果你需要从你最后的备份中做基于时间点的恢复,你也同样需要二进制日志.
log-bin=mysql-bin
# 如果你在使用链式从服务器结构的复制模式 (A->B->C),
# 你需要在服务器B上打开此项.
# 此选项打开在从线程上重做过的更新的日志, 并将其写入从服务器的二进制日志.
#log_slave_updates
# 打开全查询日志. 所有的由服务器接收到的查询 (甚至对于一个错误语法的查询)
# 都会被记录下来. 这对于调试非常有用, 在生产环境中常常关��闭此项.
#log
# 将警告打印输出到错误 log 文件. 如果你对于 MySQL 有任何问题
# 你应该打开警告 log 并且仔细审查错误日志,查出可能的原因.
#log_warnings
# 记录慢速查询. 慢速查询是指消耗了比 “long_query_time” 定义的更多时间的查询.
# 如果 log_long_format 被打开,那些没有使用索引的查询也会被记录.
# 如果你经常增加新查询到已有的系统内的话. 一般来说这是一个好主意,
log_slow_queries
# 所有的使用了比这个时间(以秒为单位)更多的查询会被认为是慢速查询.
# 不要在这里使用“1″, 否则会导致所有的查询,甚至非常快的查询页被记录下来(由于 MySQL 目前时间的精确度只能达到秒的级别).
long_query_time = 6
# 在慢速日志中记录更多的信息.
# 一般此项最好打开.
# 打开此项会记录使得那些没有使用索引的查询也被作为到慢速查询附加到慢速日志里
log_long_format
# 此目录被MySQL用来保存临时文件.例如,
# 它被用来处理基于磁盘的大型排序,和内部排序一样.
# 以及简单的临时表.
# 如果你不创建非常大的临时文件,将其放置到 swapfs/tmpfs 文件系统上也许比较好
# 另一种选择是你也可以将其放置在独立的磁盘上.
# 你可以使用”;”来放置多个路径
# 他们会按照 roud-robin 方法被轮询使用.
#tmpdir = /tmp
# *** 主从复制相关的设置
# 唯一的服务辨识号,数值位于 1 到 2^32-1之间.
# 此值在master和slave上都需要设置.
# 如果 “master-host” 没有被设置,则默认为1, 但是如果忽略此选项,MySQL不会作为master生效.
server-id = 1
# 复制的Slave (去掉master段的注释来使其生效)
#
# 为了配置此主机作为复制的slave服务器,你可以选择两种方法:
#
# 1) 使用 CHANGE MASTER TO 命令 (在我们的手册中有完整描述) -
# 语法如下:
#
# CHANGE MASTER TO MASTER_HOST=, MASTER_PORT=,
# MASTER_USER=, MASTER_PASSWORD= ;
#
# 你需要替换掉 , , 等被尖括号包围的字段以及使用master的端口号替换 (默认3306).
#
# 例子:
#
# CHANGE MASTER TO MASTER_HOST=’125.564.12.1′, MASTER_PORT=3306,
# MASTER_USER=’joe’, MASTER_PASSWORD=’secret’;
#
# 或者
#
# 2) 设置以下的变量. 不论如何, 在你选择这种方法的情况下, 然后第一次启动复制(甚至不成功的情况下,
# 例如如果你输入错密码在master-password字段并且slave无法连接),
# slave会创建一个 master.info 文件,并且之后任何对于包含在此文件内的参数的变化都会被忽略
# 并且由 master.info 文件内的内容覆盖, 除非你关闭slave服务, 删除 master.info 并且重启slave 服务.
# 由于这个原因,你也许不想碰一下的配置(注释掉的) 并且使用 CHANGE MASTER TO (查看上面) 来代替
#
# 所需要的唯一id号位于 2 和 2^32 – 1之间
# (并且和master不同)
# 如果master-host被设置了.则默认值是2
# 但是如果省略,则不会生效
#server-id = 2
#
# 复制结构中的master – 必须
#master-host =
#
# 当连接到master上时slave所用来认证的用户名 – 必须
#master-user =
#
# 当连接到master上时slave所用来认证的密码 – 必须
#master-password =
#
# master监听的端口.
# 可选 – 默认是3306
#master-port =
# 使得slave只读.只有用户拥有SUPER权限和在上面的slave线程能够修改数据.
# 你可以使用此项去保证没有应用程序会意外的修改slave而不是master上的数据
#read_only
#*** MyISAM 相关选项
# 关键词缓冲的大小, 一般用来缓冲 MyISAM 表的索引块.
# 不要将其设置大于你可用内存的30%,
# 因为一部分内存同样被OS用来缓冲行数据
# 甚至在你��并不使用 MyISAM 表的情况下, 你也需要仍旧设置起 8-64M 内存由于它同样会被内部临时磁盘表使用.
key_buffer_size = 128M
# 用来做 MyISAM 表全表扫描的缓冲大小.
# 当全表扫描需要时,在对应线程中分配.
read_buffer_size = 8M
# 当在排序之后,从一个已经排序好的序列中读取行时,行数据将从这个缓冲中读取来防止磁盘寻道.
# 如果你增高此值,可以提高很多 ORDER BY 的性能.
# 当需要时由每个线程分配
read_rnd_buffer_size = 64M
# MyISAM 使用特殊的类似树的 cache 来使得突发插入
# (这些插入是,INSERT … SELECT, INSERT … VALUES (…), (…), …, 以及 LOAD DATA INFILE) 更快.
# 此变量限制每个进程中缓冲树的字节数.
# 设置为 0 会关闭此优化.
# 为了最优化不要将此值设置大于 “key_buffer_size”.
# 当突发插入被检测到时此缓冲将被分配.
bulk_insert_buffer_size = 256M
# 此缓冲当 MySQL 需要在 REPAIR, OPTIMIZE, ALTER 以及 LOAD DATA INFILE 到一个空表中引起重建索引时被分配.
# 这在每个线程中被分配.所以在设置大值时需要小心.
myisam_sort_buffer_size = 256M
# MySQL 重建索引时所允许的最大临时文件的大小 (当 REPAIR, ALTER TABLE 或者 LOAD DATA INFILE).
# 如果文件大小比此值更大,索引会通过键值缓冲创建(更慢)
myisam_max_sort_file_size = 10G
# 如果被用来更快的索引创建索引所使用临时文件大于制定的值,那就使用键值缓冲方法.
# 这主要用来强制在大表中长字串键去使用慢速的键值缓冲方法来创建索引.
myisam_max_extra_sort_file_size = 10G
# 如果一个表拥有超过一个索引, MyISAM 可以通过并行排序使用超过一个线程去修复他们.
# 这对于拥有多个 CPU 以及大量内存情况的用户,是一个很好的选择.
myisam_repair_threads = 1
# 自动检查和修复没有适当关闭的 MyISAM 表.
myisam_recover
# 默认关闭 Federated
skip-federated
# *** BDB 相关选项 ***
# 如果你运行的MySQL服务有BDB支持但是你不准备使用的时候使用此选项. 这会节省内存并且可能加速一些事.
skip-bdb
# *** INNODB 相关选项 ***
# 如果你的 MySQL 服务包含 InnoDB 支持但是并不打算使用的话,
# 使用此选项会节省内存以及磁盘空间,并且加速某些部分
#skip-innodb
# 附加的内存池被 InnoDB 用来保存 metadata 信息(5.6中不再推荐使用)
# 如果 InnoDB 为此目的需要更多的内存,它会开始从 OS 这里申请内存.
# 由于这个操作在大多数现代操作系统上已经足够快, 你一般不需要修改此值.
# SHOW INNODB STATUS 命令�会显示当先使用的数量.
innodb_additional_mem_pool_size = 64M
# InnoDB使用一个缓冲池来保存索引和原始数据, 不像 MyISAM.
# 这里你设置越大,这能保证你在大多数的读取操作时使用的是内存而不是硬盘,在存取表里面数据时所需要的磁盘 I/O 越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
# 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
# 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
# 所以不要设置的太高.
innodb_buffer_pool_size = 6G
# InnoDB 将数据保存在一个或者多个数据文件中成为表空间.
# 如果你只有单个逻辑驱动保存你的数据,一个单个的自增文件就足够好了.
# 其他情况下.每个设备一个文件一般都是个好的选择.
# 你也可以配置 InnoDB 来使用裸盘分区 – 请参考手册来获取更多相关内容
innodb_data_file_path = ibdata1:10M:autoextend
# 设置此选项如果你希望InnoDB表空间文件被保存在其他分区.
# 默认保存在MySQL的datadir中.
#innodb_data_home_dir =
# 用来同步IO操作的IO线程的数量.
# 此值在Unix下被硬编码为8,但是在Windows磁盘I/O可能在一个大数值下表现的更好.
innodb_file_io_threads = 8
# 如果你发现 InnoDB 表空间损坏, 设置此值为一个非零值可能帮助你导出你的表.
# 从1开始并且增加此值知道你能够成功的导出表.
#innodb_force_recovery=1
# 在 InnoDb 核心内的允许线程数量.
# 最优值依赖于应用程序,硬件以及操作系统的调度方式.
# 过高的值可能导致线程的互斥颠簸.
innodb_thread_concurrency = 16
# 如果设置为1 ,InnoDB 会在每次提交后刷新(fsync)事务日志到磁盘上,
# 这提供了完整的 ACID 行为.
# 如果你愿意对事务安全折衷, 并且你正在运行一个小的事物, 你可以设置此值到0或者2来减少由事务日志引起的磁盘I/O
# 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘.
# 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上.
innodb_flush_log_at_trx_commit = 2
(说明:如��果是游戏服务器,建议此值设置为2;如果是对数据安全要求极高的应用,建议设置为1;设置为0性能最高,但如果发生故障,数据可能会有丢失的危险!默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统挂了时才可能丢数据。)
# 加速 InnoDB 的关闭. 这会阻止 InnoDB 在关闭时做全清除以及插入缓冲合并.
# 这可能极大增加关机时间, 但是取而代之的是 InnoDB 可能在下次启动时做这些操作.
#innodb_fast_shutdown
# 用来缓冲日志数据的缓冲区的大小.
# 当此值快满时, InnoDB 将必须刷新数据到磁盘上.
# 由于基本上每秒都会刷新一次,所以没有必要将此值设置的太大(甚至对于长事务而言)
innodb_log_buffer_size = 16M
# 在日志组中每个日志文件的大小.
# 你应该设置日志文件总合大小到你缓冲池大小的25%~100%
# 来避免在日志文件覆写上不必要的缓冲池刷新行为.
# 不论如何, 请注意一个大的日志文件大小会增加恢复进程所需要的时间.
innodb_log_file_size = 512M
# 在日志组中的文件总数.
# 通常来说2~3是比较好的.
innodb_log_files_in_group = 3
# InnoDB 的日志文件所在位置. 默认是 MySQL 的 datadir.
# 你可以将其指定到一个独立的硬盘上或者一个RAID1卷上来提高其性能
#innodb_log_group_home_dir
# 在 InnoDB 缓冲池中最大允许的脏页面的比例.
# 如果达到限额, InnoDB 会开始刷新他们防止他们妨碍到干净数据页面.
# 这是一个软限制,不被保证绝对执行.
innodb_max_dirty_pages_pct = 90
# InnoDB 用来刷新日志的方法.
# 表空间总是使用双重写入刷新方法
# 默认值是 “fdatasync”, 另一个是 “O_DSYNC”.
# 一般来说,如果你有硬件 RAID 控制器,并且其独立缓存采用 write-back 机制,并有着电池断电保护,那么应该设置配置为 O_DIRECT
# 否则,大多数情况下应将其设为 fdatasync
#innodb_flush_method=fdatasync
# 在被回滚前,一个 InnoDB 的事务应该等待一个锁被批准多久.
# InnoDB 在其拥有的锁表中自动检测事务死锁并且回滚事务.
# 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了 InnoDB 以外的其他事务安全的存储引擎
# 那么一个死锁可能发生而 InnoDB 无法注意到.
# 这种情况下这个 timeout 值对于解决这种问题就非常有帮助.
innodb_lock_wait_timeout = 120
# 这项设置告知InnoDB是否需要将所有表的数据和索引存放在共享表空间里(innodb_file_per_table = OFF) 或者为每张表的数据单独放在一个.ibd文件(innodb_file_per_table = ON)
# 每张表一个文件允许你在drop、truncate或者rebuild表时回收磁盘空间
# 这对于一些高级特性也是有必要的,比如数据压缩,但是它不会带来任何性能收益
innodb_file_per_table = on
[mysqldump]
# 不要在将内存中的整个结果写入磁盘之前缓存. 在导出非常巨大的表时需要此项
quick
max_allowed_packet = 32M
[mysql]
no-auto-rehash
# 仅仅允许使用键值的 UPDATEs 和 DELETEs .
#safe-updates
[myisamchk]
key_buffer = 16M
sort_buffer_size = 16M
read_buffer = 8M
write_buffer = 8M
[mysqlhotcopy]
interactive-timeout
[mysqld_safe]
# 增加每个进程的可打开文件数量.
# 警告: 确认你已经将全系统限制设定的足够高!
# 打开大量表需要将此值设大
open-files-limit = 8192
MySQL 5.6版本适合在1GB内存VPS上的my.cnf配置文件
[client]
port = 3306
socket = /tmp/mysql.sock
[mysqld]
port = 3306
socket = /tmp/mysql.sock
basedir = /usr/local/mysql
datadir = /data/mysql
pid-file = /data/mysql/mysql.pid
user = mysql
bind-address = 0.0.0.0
server-id = 1 #表示是本机的序号为1,一般来讲就是master的意思
skip-name-resolve
# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,
# 则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求
#skip-networking
back_log = 600
# MySQL能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,
# 然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。
# 如果期望在一个短时间内有很多连接,你需要增加它。也就是说,如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,
# 以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
# 另外,这值(back_log)限于您的操作系统对到来的TCP/IP连接的侦听队列的大小。
# 你的操作系统在这个队列大小上有它自己的限制(可以检查你的OS文档找出这个变量的最大值),试图设定back_log高于你的操作系统的限制将是无效的。
max_connections = 1000
# MySQL的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。可以过'conn%'通配符查看当前状态的连接数量,以定夺该值的大小。
max_connect_errors = 6000
# 对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST。
open_files_limit = 65535
# MySQL打开的文件描述符限制,默认最小1024;当open_files_limit没有被配置的时候,比较max_connections*5和ulimit -n的值,哪个大用哪个,
# 当open_file_limit被配置的时候,比较open_files_limit和max_connections*5的值,哪个大用哪个。
table_open_cache = 128
# MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。默认值64
# 假定系统有200个并发连接,则需将此参数设置为200*N(N为每个连接所需的文件描述符数目);
# 当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上
max_allowed_packet = 4M
# 接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。
# 该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出。
binlog_cache_size = 1M
# 一个事务,在没有提交的时候,产生的日志,记录到Cache中;等到事务提交需要提交的时候,则把日志持久化到磁盘。默认binlog_cache_size大小32K
max_heap_table_size = 8M
# 定义了用户可以创建的内存表(memory table)的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变
tmp_table_size = 16M
# MySQL的heap(堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。
# 大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。
# 如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySQL同时将增加heap表的大小,可达到提高联接查询速度的效果
read_buffer_size = 2M
# MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。
# 如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能
read_rnd_buffer_size = 8M
# MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,
# MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大
sort_buffer_size = 8M
# MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。
# 如果不能,可以尝试增加sort_buffer_size变量的大小
join_buffer_size = 8M
# 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享
thread_cache_size = 8
# 这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,
# 如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
# 增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。(–>表示要调整的值)
# 根据�物理内存设置规则如下:
# 1G —> 8
# 2G —> 16
# 3G —> 32
# 大于3G —> 64
query_cache_size = 8M
#MySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,
# 今后对于同样的SELECT语句(区分大小写),将直接从缓冲区中读取结果。根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率。
# 通过检查状态值'Qcache_%',可以知道query_cache_size设置是否合理:如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,
# 如果Qcache_hits的值也非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小;如果Qcache_hits的值不大,则表明你的查询重复率很低,
# 这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。此外,在SELECT语句中加入SQL_NO_CACHE可以明确表示不��使用查询缓冲
query_cache_limit = 2M
#指定单个查询能够使用的缓冲区大小,默认1M
key_buffer_size = 4M
#指定用于索引的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,
# 系统将开始换页并且真的变慢了。对于内存在4GB左右的服务器该参数可设置为384M或512M。通过检查状态值Key_read_requests和Key_reads,
# 可以知道key_buffer_size设置是否合理。比例key_reads/key_read_requests应该尽可能的低,
# 至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE 'key_read%'获得)。注意:该参数值设置的过大反而会是服务器整体效率降低
ft_min_word_len = 4
# 分词词汇最小长度,默认4
transaction_isolation = REPEATABLE-READ
# MySQL支持4种事务隔离级别,他们分别是:
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.
# 如没有指定,MySQL默认采用的是REPEATABLE-READ,ORACLE默认的是READ-COMMITTED
log_bin = mysql-bin
binlog_format = mixed
expire_logs_days = 30 #超过30天的binlog删除
log_error = /data/mysql/mysql-error.log #错误日志路径
slow_query_log = 1
long_query_time = 1 #慢查询时间 超过1秒则为慢查询
slow_query_log_file = /data/mysql/mysql-slow.log
performance_schema = 0
explicit_defaults_for_timestamp
#lower_case_table_names = 1 #不区分大小写
skip-external-locking #MySQL选项以避免外部锁定。该选项默认开启
default-storage-engine = InnoDB #默认存储引擎
innodb_file_per_table = 1
# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间
# 独立表空间优点:
# 1.每个表都有自已独立的表空间。
# 2.每个表的数据和索引都会存在自已的表空间中。
# 3.可以实现单表在不同的数据库中移动。
# 4.空间可以回收(除drop table操作处,表空不能自已回收)
# 缺点:
# 单表增加过大,如超过100G
# 结论:
# 共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整:innodb_open_files
innodb_open_files = 500
# 限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。这个值默认是300
innodb_buffer_pool_size = 64M
# InnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.
# 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
# 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
# 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
# 所以不要设置的太高.
innodb_write_io_threads = 4
innodb_read_io_threads = 4
# innodb使用后台线程处理数据页上的读写 I/O(输入输出)请求,根据你的 CPU 核数来更改,默认是4
# 注:这两个参数不支持动态改变,需要把该参数加入到my.cnf里,修改完后重启MySQL服务,允许值的范围从 1-64
innodb_thread_concurrency = 0
# 默认设置为 0,表示不限制并发数,这里推荐设置为0,更好去发挥CPU多核处理能力,提高并发量
innodb_purge_threads = 1
# InnoDB中的清除操作是一类定期回收无用数据的操作。在之前的几个版本中,清除操作是主线程的一部分,这意味着运行时它可能会堵塞其它的数据库操作。
# 从MySQL5.5.X版本开始,该操作运行于独立的线程中,并支持更多的并发数。用户可通过设置innodb_purge_threads配置参数来选择清除操作是否使用单
# 独线程,默认情况下参数设置为0(不使用单独线程),设置为 1 时表示使用单独的清除线程。建议为1
innodb_flush_log_at_trx_commit = 2
# 0:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
# 主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile1
# 1:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。
# 2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。
# 每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘
# 默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。
# 设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。
# 总结
# 设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能
innodb_log_buffer_size = 2M
# 此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL开发人员建议设置为1-8M之间
innodb_log_file_size = 32M
# 此参数确定数据日志文件的大小,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间
innodb_log_files_in_group = 3
# 为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3
innodb_max_dirty_pages_pct = 90
# innodb主线程刷新缓存池中的数据,使脏数据比例小于90%
innodb_lock_wait_timeout = 120
# InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒
bulk_insert_buffer_size = 8M
# 批量插入缓存大小, 这个参数是针对MyISAM存储引擎来说的。适用于在一次性插入100-1000+条记录时, 提高效率。默认值是8M。可以针对数据量的大小,翻倍增加。
myisam_sort_buffer_size = 8M
# MyISAM设置恢复表之时使用的缓冲区的尺寸,当在REPAIR TABLE或用CREATE INDEX创建索引或ALTER TABLE过程中排序 MyISAM索引分配的缓冲区
myisam_max_sort_file_size = 10G
# 如果临时文件会变得超过索引,不要使用快速排序索引方法来创建一个索引。注释:这个参数以字节的形式给出
myisam_repair_threads = 1
# 如果该值大于1,在Repair by sorting过程中并行创建MyISAM表索引(每个索引在自己的线程内)
interactive_timeout = 28800
# 服务器关闭交互式连接前等待活动的秒数。交互式客户端定义为在mysql_real_connect()中使用CLIENT_INTERACTIVE选项的客户端。默认值:28800秒(8小时)
wait_timeout = 28800
# 服务器关闭非交互连接之前等待活动的秒数。在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,
# 取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)。参数默认值:28800秒(8小时)
# MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQL Server处理完相应的操作后,
# 应该断开连接并释放占用的内存。如果你的MySQL Server有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,
# 最终肯定会达到MySQL Server的连接上限数,这会报'too many connections'的错误。对于wait_timeout的值设定,应该根据系统的运行情况来判断。
# 在系统运行一段时间后,可以通过show processlist命令查看当前系统的连接状态,如果发现有大量的sleep状态的连接进程,则说明该参数设置的过大,
# 可以进行适当的调整小些。要同时设置interactive_timeout和wait_timeout才会生效。
[mysqldump]
quick
max_allowed_packet = 16M #服务器发送和接受的最大包长度
[myisamchk]
key_buffer_size = 8M
sort_buffer_size = 8M
read_buffer = 4M
write_buffer = 4M
Linux 加密脚本
gzexe会把原来没有加密的文件备份为 test.sh~ ,同时test.sh 即被变成加密文件
gzexe test.sh
gzexe解密
提取解密后的压缩文件1.gz到/tmp目录,其中的+44为上面的示例脚本中对应的乱码开始
/usr/bin/tail -n +44 file.sh >/tmp/1.gz
gunzip /tmp/1.gz
shc安装
wget http://www.datsi.fi.upm.es/~frosal/sources/shc-3.8.9.tgz
tar xzvf shc-3.8.9.tgz
cd shc-3.8.9
mkdir -p /usr/local/man/man1
make install
shc加密
shc -r -f test.sh
运行后会生成两个文件test.sh.x 和 test.sh.x.c test.sh.x:是加密后的可执行的二进制文件./test.sh.x 即可运行. test.sh.x.c:是生成test.sh.x的原文件(c语言,可以直接删掉)
参数
- -e: 指定过期时间为20/10/2020(2020年10月20日)
- -m: 过期后打印出的信息;
- -v: 编译的详细情况
- -r: 可在相同操作系统的不同主机上执行
- -f: 指定源shell
DELL服务器硬件信息查看
查看机器型号
dmidecode | grep "Product"
查看厂商
dmidecode | grep "Manufacturer"
查��看序列号
dmidecode | grep "Serial Number"
查看CPU信息
dmidecode | grep "CPU"
查看CPU个数
dmidecode | grep "Socket Designation: CPU" |wc –l
查看出厂日期
dmidecode | grep "Date"
查看充电状态
MegaCli -AdpBbuCmd -GetBbuStatus -aALL |grep "Charger Status"
显示BBU状态信息
MegaCli -AdpBbuCmd -GetBbuStatus –aALL
显示BBU容量信息
MegaCli -AdpBbuCmd -GetBbuCapacityInfo –aALL
显示当前BBU属性
MegaCli -AdpBbuCmd -GetBbuProperties –aALL
查看充电进度百分比
MegaCli -AdpBbuCmd -GetBbuStatus -aALL |grep "Relative State of Charge"
查询Raid阵列数
MegaCli -cfgdsply -aALL |grep "Number of DISK GROUPS:"
显示Raid卡型号,Raid设置,Disk相关信息
MegaCli -cfgdsply –aALL
显示所有物理信息
MegaCli -PDList -aALL
显示所有逻辑磁盘组信息
MegaCli -LDInfo -LALL –aAll
查看物理磁盘��重建进度(重要)
MegaCli -PDRbld -ShowProg -PhysDrv [1:5] -a0
查看适配器个数
MegaCli –adpCount
查看适配器时间
MegaCli -AdpGetTime –aALL
显示所有适配器信息
MegaCli -AdpAllInfo –aAll
查看Cache 策略设置
MegaCli -cfgdsply -aALL |grep Polic
硬盘方面:
1、查看所有物理磁盘信息
MegaCli -PDList -aALL
Adapter #0
Enclosure Number: 1
Slot Number: 5
Device Id: 5
Sequence Number: 2
Media Error Count: 0
Other Error Count: 0
Predictive Failure Count: 0
Last Predictive Failure Event Seq Number: 0
Raw Size: 140014MB [0x11177328 Sectors]
Non Coerced Size: 139502MB [0x11077328 Sectors]
Coerced Size: 139392MB [0x11040000 Sectors]
Firmware state: Hotspare
SAS Address(0): 0x5000c50008e5cca9
SAS Address(1): 0x0
Inquiry Data: SEAGATE ST3146855SS S5273LN4Y1X0
.....
2、查看磁盘缓存策略
MegaCli -LDGetProp -Cache -L0 -a0
Adapter 0-VD 0: Cache Policy:WriteBack, ReadAheadNone, Direct
or
MegaCli -LDGetProp -Cache -L1 -a0
Adapter 0-VD 1: Cache Policy:WriteBack, ReadAheadNone, Direct
or
MegaCli -LDGetProp -Cache -LALL -a0
Adapter 0-VD 0: Cache Policy:WriteBack, ReadAheadNone, Direct
Adapter 0-VD 1: Cache Policy:WriteBack, ReadAheadNone, Direct
or
MegaCli -LDGetProp -Cache -LALL -aALL
Adapter 0-VD 0: Cache Policy:WriteBack, ReadAheadNone, Direct
Adapter 0-VD 1: Cache Policy:WriteBack, ReadAheadNone, Direct
or
MegaCli -LDGetProp -DskCache -LALL -aALL
Adapter 0-VD 0: Disk Write Cache : Disk's Default
Adapter 0-VD 1: Disk Write Cache : Disk's Default
3、设置磁盘缓存策略
- WT (Write through)
- WB (Write back)
- NORA (No read ahead)
- RA (Read ahead)
- ADRA (Adaptive read ahead)
MegaCli -LDSetProp WT|WB|NORA|RA|ADRA -L0 -a0
or
MegaCli -LDSetProp -Cached|-Direct -L0 -a0
or
enable / disable disk cache
MegaCli -LDSetProp -EnDskCache|-DisDskCache -L0 -a0
4、创建/删除 阵列
创建一个 raid5 阵列,由物理盘 2,3,4 构成,该阵列的热备盘是物理盘 5
MegaCli -CfgLdAdd -r5 [1:2,1:3,1:4] WB Direct -Hsp[1:5] –a0
创建阵列,不指定热备
MegaCli -CfgLdAdd -r5 [1:2,1:3,1:4] WB Direct –a0
删除阵列
MegaCli -CfgLdDel -L1 –a0
在线添加磁盘
MegaCli -LDRecon -Start -r5 -Add -PhysDrv[1:4] -L1 -a0
意思是,重建逻辑磁盘组1,raid级别是5,添加物理磁盘号:1:4。重建完后,新添加的物理磁盘会自动处于重建(同步)状态,这个 时候 fdisk -l是看不到阵列的空间变大的,只有在系统重启后才能看见。
5、查看阵列初始化信息
阵列创建完后,会有一个初始化同步块的过程,可以看看其进度。
MegaCli -LDInit -ShowProg -LALL -aALL
或者以动态可视化文字界面显示
MegaCli -LDInit -ProgDsply -LALL –aALL
查看阵列后台初始化进度
MegaCli -LDBI -ShowProg -LALL -aALL
或者以动态可视化文字界面显示
MegaCli -LDBI -ProgDsply -LALL -aALL
6、创建全局热备 指定第 5 块盘作为全局热备
MegaCli -PDHSP -Set [-EnclAffinity] [-nonRevertible] -PhysDrv[1:5] -a0
也可以指定为某个阵列的专用热备
MegaCli -PDHSP -Set [-Dedicated [-Array1]] [-EnclAffinity] [-nonRevertible] -PhysDrv[1:5] -a0
7、删除全局热备
MegaCli -PDHSP -Rmv -PhysDrv[1:5] -a0
8、将某块物理盘下线/上线
MegaCli -PDOffline -PhysDrv [1:4] -a0
MegaCli -PDOnline -PhysDrv [1:4] -a0
9、查看物理磁盘重建进度
MegaCli -PDRbld -ShowProg -PhysDrv [1:5] -a0
普通账号后再使用su -命令切换回root提示"incorrect password"
chmod 4755 /bin/su
不打印空行和注释
grep '^[a-Z]' filename
egrep -v "(^#|^$)" filename
虚拟机在线添加磁盘
echo "- - -" > /sys/class/scsi_host/host2/scan
iptables通过lokkit开放端口
yum install -y lokkit
开放8000端口
lokkit -p 8000:tcp
查看libstdc库对应版本型号
strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
fork 炸弹
linux:
:(){ :|:& };:
windows:
cmd /c @cd /d %temp% & echo @start /min cmd ^& cmd > cmd.bat & cmd
多个外网ip指定出口ip
iptables -t nat -A POSTROUTING -s 0.0.0.0/0 -j SNAT --to-source 出口地址
iptables -t nat -I POSTROUTING -d 0.0.0.0/0 -s 默认出口地址 -j SNAT --to-source 指定出口地址
ssh反向代理
局域网主机:
ServerA / Linux / user userA / ip192.168.0.123 / ssh port 22
ServerB / Linux / user userB / ip192.168.0.125 / ssh port 22
PC / Windows / ip 192.168.0.128 / 远程桌面 port3389
远程主机:
MyServer / Linux / user me / ip 1.2.3.4 /ssh port 22
ssh参数:
- -N:不执行何指令
- -f:后台执行
- -R:建立reverse tunnel
示例1:从MyServer ssh连回ServerA
[userA@ServerA] $ ssh -NfR2222:localhost:22 me@MyServer
[me@MyServer] $ netstat -tnl | grep 127.0.0.1
tcp 0 0 127.0.0.1:2222 0.0.0.0:* LISTEN
[me@MyServer] $ ssh userA@127.0.0.1 -p 2222
MyServer连到2222 port会转向ServerA的ssh port,成功连接到ServerA
示例2:从MyServer ssh连回ServerB
[userA@ServerA] $ ssh -NfR 2244:192.168.0.125:22me@MyServer
[me@MyServer] $ netstat -tnl | grep127.0.0.1
tcp 0 0 127.0.0.1:2244 0.0.0.0:* LISTEN
[me@MyServer] $ ssh userB@127.0.0.1 -p 2244
MyServer连接到本机的2244 port会转向到ServerB的ssh port,成功连接到ServerB
示例3:从MyServer远程桌面PC
[userA@ServerA] $ ssh -NfR2266:192.168.0.128:3389 me@MyServer
[me@MyServer] $ netstat -tnl | grep127.0.0.1
tcp 0 0 127.0.0.1:2266 0.0.0.0:* LISTEN
[me@MyServer] $ rdesktop 127.0.0.1:2266
若你在Linux的桌面环境则可以直接display远程桌面PC,不然就export DISPLAY到其他主机。
此外,为了防止反向的Tunnel断开,还需要一个autossh工具,它可以帮助断线后自动重连。这个对我相当的重要,事实上我现在很少去B集群所在的地方。
对示例一做autossh可以如此做:
[userA@ServerA] $ autossh -M 12345-NfR2222:localhost:22 me@MyServer
当然,为了防止集群重启或断电等问题,可以将上语句写到开机启动脚本里。
linux端口转发
开启数据包转发
echo 1 > /proc/sys/net/ipv4/ip_forward
转发本地端口8081到8080
iptables -t nat -A PREROUTING -p tcp --dport 8081 -j REDIRECT --to-port 8080
转发TCP 8081到xx.xx.xx.xx的80端口
iptables -t nat -I PREROUTING -p tcp --dport 8081 -j DNAT --to xx.xx.xx.xx:80
使转发数据包实现“双向通路”,给数据包设置一个正确的返回通道
iptables -t nat -I POSTROUTING -p tcp --dport 8081 -j MASQUERADE
将规则保存到/etc/sysconfig/iptables文件
service iptables save
重启iptables使刚才添加的规则生效
service iptables restart
将访问192.168.10.10主机888端口的请求转发至22端口
firewll-cmd --permanent --zone=public --add-forward-port=port=888:proto=ssh:toport=22:toaddr=192.168.10.10
另外流量均衡技术也是常用的技术,比如将一台主机作为网站的前端服务器,将访问流量分流至内网中3台不同的主机上。
iptables -A PREROUTING -i eth0 -p tcp --dport 80 -m state --state NEW -m nth --counter 0 --every 3 --packet 0 -j DNAT --to-destination 192.168.10.10:80
iptables -A PREROUTING -i eth0 -p tcp --dport 80 -m state --state NEW -m nth --counter 0 --every 3 --packet 0 -j DNAT --to-destination 192.168.10.11:80
iptables -A PREROUTING -i eth0 -p tcp --dport 80 -m state --state NEW -m nth --counter 0 --every 3 --packet 0 -j DNAT --to-destination 192.168.10.12:80
乱码名字文件通过inode修改文件名字
ls -i
find -inum 文件的inode -exec mv {} 新名称 \;
Shell参数
文件测试
-
[ -d /etc/fstab ] 测试/etc/fstab/是否为文件
-
-d 测试是否为目录
-
-e 测试文件或目录是否存在
-
-f 判断是否为文件
-
-r 测试当前用户是否有权限读取
-
-w 测试当前用户是否有权限写入
-
-x 测试当前用户是否有权限执行
逻辑测试
- && 逻辑的与,“而且”的意思
- || 逻辑的或,“或者”的意思
- ! 逻辑的否
整数值比较
-
[ 10 -eq 10 ] 比较10是否等于10
-
-eq 判断是否等于
-
-ne 判断是否不等于
-
-gt 判断是否大于
-
-lt 判断是否小于
-
-le 判断是否等于或小于
-
-ge 判断是否大于或等于
字符串比较
-
[ -z $test ] 判断变量是否为空值
-
[ $LANG != "en.US" ] 判断当前系统语言是否为英文
-
= 比较字符串内容是否相同
-
!= 比较字符串内容是否不同
-
-z 判断字符串内容是否为空
升级zabbix
备份zabbix数据库
mysqldump -u root -p123456 --opt --skip-lock-tables --flush-logs --database zabbix > zabbix.sql
备份php源代码
cd /usr/local/apache2/htdocs
mv zabbix zabbix.bak
将原PHP源代码目录下的配置文件拷到新目录下
cp zabbix.bak/conf/zabbix.conf.php zabbix/conf/
关闭zabbix系统服务(服务端和客户端)
/etc/init.d/zabbix_server stop
/etc/init.d/zabbix_agentd stop
安装新zabbix
tar zxvf zabbix-2.2.0rc2.tar.gz
cd zabbix-2.2.0rc2
./configure --enable-server --enable-agent --with-mysql --enable-ipv6 --with-net-snmp --with-libcurl
make install
Linux网页管理工具
webmin( Unix系统管理工具)
wget http://prdownloads.sourceforge.net/webadmin/webmin-1.740.tar.gz
tar zxf webmin-1.740.tar.gz
cd webmin-1.740
./setup.sh /usr/local/webmin
AppNode(高扩展 Linux 服务器管理面板)
bash -c "$(curl http://dl.appnode.com/install.sh)"
Ajenti( 轻型Linux 服务器管理面板 )
bash -c "$(curlhttps://raw.githubusercontent.com/Eugeny/ajenti/master/scripts/install-rhel.sh)"
centos6.5升级到centos7
redhat提供了一个redhat-upgrade-tool的升级工具
配置软件源
vi /etc/yum.repos.d/upgrade.repo
[upgrade]
name=upgrade
baseurl=http://dev.centos.org/centos/6/upg/x86_64/
enable=1
gpgcheck=0
安装软件工具
yum -y install preupgrade-assistant-contents redhat-upgrade-tool preupgrade-assistant
升级前检查潜在问题
preupg
开始升级
rpm --import http://mirror.centos.org/centos/RPM-GPG-KEY-CentOS-7
redhat-upgrade-tool --network 7.0 --instrepo http://centos.excellmedia.net/7.0.1406/os/x86_64/
重启
reboot
安装zabbix报错解决方法
configure: error: Jabber library not found
yum install iksemel-devel
configure: error: LIBXML2 library not found
yum install libxml2-devel
configure: error: unixODBC library not found
yum install unixODBC-devel
configure: error: Invalid OPENIPMI directory - unable to findipmiif.h
yum install OpenIPMI-devel
configure:error: Unable to find "javac" executable in path
yum install java*
configure: error: Curl library not found
yum install curl-devel
调整根分区大小
使用光盘进入Rescue installed system 依次选择不加载网络不挂载文件系统进入命令行
vgscan #显示卷组
vgchange -ay /dev/volGroup00 #卷组
e2fsck -f /dev/volGroup00/LogVol00 #检查磁盘是否正确
resize2fs -p /dev/volGroup00/LogVol00 10G #设置LogVol00卷组大小为10G
fsck /dev/volGroup00/LogVol00 #修复错误
lvreduce -L 10G /dev/volGroup00/LogVol00 #收缩LogVol00卷组大小为10G
umount /data #取消挂载
lvextend -L +4G /dev/volGroup00/LogVol01 #增加LogVol01卷组大小
resize2fs -p /dev/volGroup00/LogVol01 #df看不到空间增加使用此命令激活
linux连接wpa加密的wifi
生成psk
wpa_passphrase ssid passwd
把生成的psk加入配置文件/etc/wpa_supplicant.conf
ctrl_interface=/var/run/wpa_supplicant
ctrl_interface_group=wheel
network={
ssid="TP-LINK_413"
#psk=""
psk=e69abb9b46dcbf8df67738a2eda466c54b3f12043e54157d58e097c3e19fa2e3
proto=RSN
key_mgmt=WPA-PSK
pairwise=CCMP TKIP
group=CCMP TKIP
}
连接wifi
wpa_supplicant -Dwext -iwlan0 -c/etc/wpa_supplicant.conf -dd -B
系统初始化脚本
#!/bin/bash
if [ $(id -u) != 0 ];then
echo "Must be root can do this."
exit 9
fi
# set privileges
chmod 600 /etc/passwd
chmod 600 /etc/shadow
chmod 600 /etc/group
chmod 600 /etc/gshadow
echo "Set important files privileges sucessfully"
#close ctrl+alt+del
sed -i "s/ca::ctrlaltdel:\/sbin\/shutdown -t3 -r now/#ca::ctrlaltdel:\/sbin\/shutdown -t3 -r now/" /etc/inittab
sed -i 's/^id:5:initdefault:/id:3:initdefault:/' /etc/inittab
#close ipv6
echo "alias net-pf-10 off" >> /etc/modprobe.conf
echo "alias ipv6 off" >> /etc/modprobe.conf
/sbin/chkconfig --level 35 ip6tables off
echo -e "\033[031m ipv6 is disabled.\033[0m"
#shutdown SELinux
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
echo -e "\033[31m selinux is disabled,if you need,you must reboot.\033[0m"
sed -i "8 s/^/alias vi='vim'/" /root/.bashrc
echo 'syntax on' > /root/.vimrc
#update yum source
mv -f /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
curl -s http://mirrors.163.com/.help/CentOS6-Base-163.repo -o /etc/yum.repos.d/CentOS-Base.repo
yum clean all
yum makecache
#install common software
yum -y install openssh-clients man wget yum-utils vim-enhanced lrzsz telnet traceroute glibc-headers gcc make autoconf libtool automake gcc-c++ openssl openssl-devel unzip zip lrzsz openssl openssl-devel pcre pcre-devel gcc make automake vim
#Turn off unnecessary services
service=($(ls /etc/init.d/))
for i in ${service[@]}; do
case $i in
sshd|network|syslog|crond)
chkconfig $i on;;
*)
chkconfig $i off;;
esac
done
#set ulimit
cat >> /etc/security/limits.conf << EOF
* soft nofile 165535
* hard nofile 165535
EOF
# set sysctl
cat > /etc/sysctl.conf << EOF
net.ipv4.ip_forward = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
kernel.sysrq = 0
kernel.core_uses_pid = 1
kernel.msgmnb = 65536
kernel.msgmax = 65536
kernel.shmmax = 68719476736
kernel.shmall = 4294967296
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_sack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_rmem = 4096 87380 4194304
net.ipv4.tcp_wmem = 4096 16384 4194304
net.core.wmem_default = 8388608
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.netdev_max_backlog = 262144
net.core.somaxconn = 262144
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 262144
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_mem = 94500000 915000000 927000000
net.ipv4.tcp_fin_timeout = 1
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.ip_local_port_range = 1024 65535
vm.swappiness = 0
EOF
echo "0 0 * * * /usr/sbin/ntpdate cn.pool.ntp.org &>/dev/null" >>/var/spool/cron/root
echo "All things is init ok! "
查看cpu信息
总核数 = 物理CPU个数 X 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看所有cpu信息
lscpu
svn迁移
如果不包括日志,只需要checkout最新版本,svn export出干净的项目,然后import到新的服务器的svn. 如果需要日志,方法如下:
把项目的各个版本dump出来
svnadmin dump /path/to/repository > repo_name.svn_dump
在新的服务器上创建新的知识库
svnadmin create /path/to/repository
把项目载入到知识库里
svnadmin load /path/to/repository < repo_name.svn_dump
拷贝源服务器上的配置文件 authz passwd svnserve.conf
vim 快捷键
| 命令 | 功能 |
|---|---|
| u | 撤销上一步的操作 |
| Ctrl+r | 恢复上一步被撤销的操作 |
| :%s/^ // | 删除行首空格 |
| :%s/r//g | 删除DOS方式的回车^M |
| :%s= *$== | 删除行尾空白 |
| :%s/^(.*)n1/1$/ | 删除重复行 |
| :%s/^.pdf/new.pdf/ | 只是删除第一个pdf |
| :g/^s*$/d | 删除所有空行 |
| :g!/^dd/d | 删除不含字符串'dd'的行 |
| :v/^dd/d | 同上 (译释:v == g!,就是不匹配!) |
| :g/str1/,/str2/d | 删除所有第一个含str1到第一个含str2之间的行 |
| :v/./.,/./-1join | 合并连续空行 |
| :g/^$/,/./-j | 合并连续空行 |
| ndw 或 ndW | 删除光标处开始及其后的 n-1 个字符 |
| d0 | 删至行首 |
| d$ | 删至行尾 |
| ndd | 删除当前行及其后 n-1 行 |
| x 或 X | 删除一个字符 |
| Ctrl+u | 输入模式下删除当前所输入的文本 |
| ^R | 恢复u的操作 |
| J | 把下一行合并到当前行尾 |
| V | 选择一行 |
| ^V | 按下^V后即可进行矩形的选择了 |
| aw | 选择单词 |
| iw | 内部单词(无空格) |
| as | 选择句子 |
| is | 选择句子(无空格) |
| ap | 选择段落 |
| ip | 选择段落(无空格) |
| D | 删除到行尾 |
| x,y | 删除与复制包含高亮区 |
| dl | 删除当前字符(与x命令功能相同) |
| d0 | 删除到某一行的开始位置 |
| d^ | 删除到某一行的第一个字符位置(不包括空格或TAB字符) |
| dw | 删除�到某个单词的结尾位置 |
| d3w | 删除到第三个单词的结尾位置 |
| db | 删除到某个单词的开始位置 |
| dW | 删除到某个以空格作为分隔符的单词的结尾位置 |
| dB | 删除到某个以空格作为分隔符的单词的开始位置 |
| d7B | 删除到前面7个以空格作为分隔符的单词的开始位置 |
| d) | 删除到某个语句的结尾位置 |
| d4) | 删除到第四个语句的结尾位置 |
| d( | 删除到某个语句的开始位置 |
| d) | 删除到某个段落的结尾位置 |
| d{ | 删除到某个段落的开始位置 |
| d7{ | 删除到当前段落起始位置之前的第7个段落位置 |
| dd | 删除当前行 |
| d/text | 删除从文本中出现“text”中所指定字样的位置,一直向前直到下一个该字样所出现的位置(但不包括该字样)之间的内容 |
| dfc | 删除从文本中出现字符“c”的位置,一直向前直到下一个该字符所出现的位置(包括该字符)之间的内容 |
| dtc | 删除当前行直到下一个字符“c”所出现位置之间的内容 |
| D | 删除到某一行的结尾 |
| d$ | 删除到某一行的结尾 |
| 5dd | 删除从当前行所开始的5行内容 |
| dL | 删除直到屏幕上最后一行的内容 |
| dH | 删除直到屏幕上第一行的内容 |
| dG | 删除直到工作缓存区结尾的内容 |
| d1G | 删除直到工作缓存区开始的内容 |
挂载ntfs分区
步骤一:解压安装NTFS-3G。 tar -xvzf ntfs-3g_ntfsprogs-2012.1.15.tgz cd ntfs-3g_ntfsprogs-2012.1.15 执行安装过程如下所示: ./configure make make install 之后系统会提示安装成功,下面就可以用ntfs-3g来实现对NTFS分区的读写了
步骤二:配置挂载NTFS格式的移动硬盘
-
首先得到NTFS分区的信息 fdisk -l | grep NTFS
-
设置挂载点,用如下命令实现挂载 mount -t ntfs-3g [NTFS Partition] [Mount Point]
例如得到的NTFS分区信息为/dev/sdc1,挂载点设置在/mnt/usb下,可以用 mount -t ntfs-3g /dev/sdc1 /mnt/usb 或者直接用 ntfs-3g ntfs-3g /dev/sdc1 /mnt/usb
- 如果想实现开机自动挂载,可以在/etc/fstab里面添加如下格式语句 [NTFS Partition] [Mount Point] ntfs-3g silent,umask=0,locale=zh_CN.utf8 0 0 这样可以实现NTFS分区里中文文件名的显示。
修改单个用户字符集
vi ~/.bashrc
export LC_CTYPE="zh_CN.gbk"
查看服务器硬件信息
yum install epel-release
yum install inxi
- inxi -A 显示音频信息
- inxi -G 显示显卡信息
- inxi -D 显示硬盘信息
- inxi -M 显示主板信息
- inxi -r 显示可用仓库列表
- inxi -F 显示全部信息
zabbix监控exsi
编译安装
./configure --prefix=/usr/local/zabbix --enable-server --enable-agent --with-mysql --with-net-snmp --with-libcurl --with-libxml2
配置文件添加参数
StartVMwareCollectors=50
VMwareFrequency=60
VMwareCacheSize=128M
服务器网络死掉
查看网卡流量状况,是哪个ip
iptraf
发现流量不正常的IP,使用iptables封掉
iptables -I OUTPUT -d IP地址 -j DROP
封掉所有UDP端口
iptables -I OUTPUT -p UDP -j DROP
查看网络连接数
netstat -n | awk '/^tcp/ {n=split($(NF-1),array,":");if(n<=2)++S[array[(1)]];else++S[array[(4)]];++s[$NF];++N} END {for(a in S){printf("%-20s %s\n", a, S[a]);++I}printf("%-20s %s\n","TOTAL_IP",I);for(a in s) printf("%-20s %s\n", a, s[a]);printf("%-20s %s\n","TOTAL_LINK",N);}'
批量修改服务器密码
创建服务器列表文件,格式如下(前边是IP,中间是当前登陆密码,第三列是要修改的密码)
vi iplist.txt
192.168.1.100 123456 123abc
192.168.1.101 654321 abc123
创建expect交互式脚本
#!/usr/bin/expect -f
set IP [lindex $argv 0] ##设置IP为第一个带入项,也就是上边脚本的$i
set PASSWORD [lindex $argv 1] ##同理,第二个带入项,$y
set NEWPASSWORD [lindex $argv 2] ##同理,第三个带入项,$z
spawn ssh $IP " echo '$NEWPASSWORD'| passwd --stdin root " ##spawn后边跟要执行的命令,此例是把root密码改成iplist.txt中的第三列的数值
expect {
"(yes/no)" { send "yes\r"; exp_continue } ##如果第一次登陆,就发送yes
"password:" { send "$PASSWORD\r"; exp_continue } ##发送登陆密码
"*?" { send "\r" } ##没有交互直接发个回车
}
interact
exit
创建一个bash脚本,通过for循环读取IP和密码,然后给expect脚本
#!/bin/bash
for i in `awk '{print $1}' iplist.txt`
do
y=`awk /${i}/'{print $2}' iplist.txt`
z=`awk /${i}/'{print $3}' iplist.txt`
./expect.sh ${i} ${y} ${z}
done
配置ssh信任关系
ssh-keygen -t rsa
ssh-copy-id root@172.16.1.3
ansible使用
远程文件信息查看
ansible storm_cluster -m command -a "ls -al /tw/test.sh"
将本地文件/etc/ansible/ansible.cfg复制到远程服务器
ansible storm_cluster -m copy -a "src=/etc/ansible/ansible.cfg dest=/tmp/ansible.cfg owner=root group=root mode=0644"
在远程主机上执行命令
ansible storm_cluster -m command -a "uptime"
远程执行脚本
ansible storm_cluster -m shell -a "/tmp/test.sh"
查看设备OID值
安装snmpwalk
yum -y install net-snmp-utils
获取端口
snmpwalk 10.6.9.1 -v1 -c public|grep -i ifinoctet
注:默认端口排序WAN1(256)、WAN2(257)、VLAN1(258)、LAN1(1794)、LAN2(1795)......LAN10、Loopback(2816)
查看端口oid
snmpget -v1 -c public -On 10.6.9.1 ifInOctets.256
ssh登录错误次数较多的IP用iptables封掉脚本
#!/bin/bash
num=10 #上限
for i in `awk '/Failed/{print $(NF-3)}' /var/log/secure|sort|uniq -c|sort -rn|awk '{if ($1>$num){print $2}}'`
do
iptables -I INPUT -p tcp -s $i --dport 22 -j DROP
done
iptables添加多个端口脚本
#!/bin/bash
SERVICES="80 22 25 110 8000 23 20 21 3306"
for x in $SERVICES
do
iptables -A INPUT -p tcp --dport $x -m state --state NEW -j ACCEPT
done
ssh连接只显示-bash-4.1#
vi ~/.bash_profile
export PS1='[\u@\h \W]\$’
iptables 设置限制mac地址
允许MAC地址为XX:XX:XX:XX:XX:XX主机访问22端口
iptables -A INPUT -p tcp --destination-port 22 -m mac --mac-source XX:XX:XX:XX:XX:XX -j ACCEPT
不重启关闭selinux
设置SELinux 成为enforcing模式
setenforce 1
设置SELinux 成为permissive模式
setenforce 0
添加高级路由
路由表目录: /etc/iproute2/rt_tables
创建一个路由表test
echo "252 test" >> /etc/iproute2/rt_tables
定义test表默认路由去往10.10.0.1网关
ip route add default via 10.10.0.1 dev em1 table test
10.10.10.2应用test路由表
ip rule add from 10.10.10.2 table test
10.0.0.0/16这个段ip应用test路由表(pref 1000为优先级)
ip rule add to 10.0.0.0/16 pref 1000 table test
查询ip路由信息
ip route get 8.8.8.8
mtr 8.8.8.8
修改ssh基于密码验证
vi /etc/ssh/sshd_config
PasswordAuthentication yes
安装logwatch
rpm -Uvh ftp://ftp.kaybee.org/pub/redhat/RPMS/noarch/logwatch-7.3.6-1.noarch.rpm
You have new mail in /var/spool/mail/root 解决方法
echo "unset MAILCHECK" >> /etc/profile
设置自动同步时间
crontab -e 加入 */30 * * * * /usr/sbin/ntpdate time.windows.com (每30分钟同步一次) */30 * * * * /usr/sbin/ntpdate us.pool.ntp.org */30 * * * * /usr/sbin/ntpdate time.nist.gov
安装sz rz命令
yum install lrzsz
yum无pptpd
rpm -Uvh http://poptop.sourceforge.net/yum/stable/pptp-release-current.noarch.rpm
yum -y install pptpd
升级GCC后使用filezilla报错
执行命令查看有没有相应的库
strings /usr/lib64/libstdc++.so.6 | grep GLIBCXX
linux 安装DNS
caching-nameserver(除bind以外的另一个安装包)
安装本地rpm包
yum localinstall --nogpgcheck rpmname
ipsec安装
yum -y install openswan
测试硬盘读写速度
dd if=/root/1Gb.file bs=64k | dd of=/dev/null
dd if=/dev/zero of=/root/1Gb.file bs=1024 count=1000000
通过上两个命令输出的执行时间,可以计算出测试硬盘的读/写速度
销毁磁盘数据
dd if=/dev/urandom of=/dev/hda1
利用随机的数据填充硬盘,在某些必要的场合可以用来销毁数据。执行此操作以后,/dev/hda1将无法挂载,创建和拷贝操作无法执行。
查看系统所有用户和组
所有用户
cut -d: -f1 /etc/passwd
所有组
cut -d: -f1 /etc/group
查看用户登录日志
last
查看系统版本
cat /etc/redhat-release
lsb_release -a
yum install -y redhat-lsb 安装lsb_release命令
输出最为常用的十条命令
history|awk '{CMD[$2]++;count++;} END {for(a in CMD)print CMD[a]" "CMD[a]/count*100 "% " a}'|grep -v "./"|column -c3 -s " " -t|sort -nr|nl|head -n10
anaconda-ks.cfg
# Kickstart file automatically generated by anaconda.
#version=DEVEL
install
text
cdrom
lang en_US.UTF-8
keyboard us
network --onboot no --device em1 --bootproto dhcp --noipv6
network --onboot no --device em2 --bootproto dhcp --noipv6
rootpw abcu123456
firewall --disabled
authconfig --enableshadow --passalgo=sha512
selinux --disabled
timezone --utc Asia/Shanghai
bootloader --location=mbr --driveorder=sda --append="crashkernel=auto rhgb quiet"
# The following is the partition information you requested
# Note that any partitions you deleted are not expressed
# here so unless you clear all partitions first, this is
# not guaranteed to work
#clearpart --none
clearpart --all --initlabel
zerombr
part /boot --fstype=ext4 --size=200
part swap --size=32000
part pv.008003 --grow --size=200
ignoredisk --only-use=sda
volgroup volGroup00 --pesize=4096 pv.008003
logvol / --fstype=ext4 --name=LogVol00 --vgname=volGroup00 --size=200000
logvol /data --fstype=ext4 --name=LogVol01 --vgname=volGroup00 --size=1655232
reboot
#repo --name="CentOS" --baseurl=cdrom:sr0 --cost=100
%packages
@chinese-support
@core
@server-policy
%end
linux 卸载rpm
rpm -aq|grep rpmname |xargs rpm -e --nodeps
安装GBD出现 cc1plus: warnings being treated as errors 错误解决方法
./configure --prefix=/usr/local/gdb --with-mpc=/usr/local/mpc --with=mpfr=/usr/local/mpfr --with-gmp=/usr/local/gmp/ --disable-werror
沒有nslookup、host、dig命令
yum install bind-utils
配置多个tomcat
1、�两个tomcat路径
/usr/local/tomcat /usr/local/tomcat2
2、配置环境变量,在/etc/profile最后添加:
TOMCAT_HOME_1=/usr/local/tomcat
export CATALINA_BASE_1=/usr/local/tomcat
export CATALINA_HOME_1=/usr/local/tomcat
export TOMCAT_HOME_1 CATALINA_BASE_1 CATALINA_HOME_1
TOMCAT_HOME_2=/usr/local/tomcat2
export CATALINA_BASE_2=/usr/local/tomcat2
export CATALINA_HOME_2=/usr/local/tomcat2
export TOMCAT_HOME_2 CATALINA_BASE_2 CATALINA_HOME_2
3、修改tomcat2启动、关闭脚本,最后分别添加如下:
/usr/local/tomcat2/bin/start.sh /usr/local/tomcat2/bin/shutdown.sh
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=$JAVA_HOME/lib
export CATALINA_HOME=$CATALINA_HOME_2
export CATALINA_BASE=$CATALINA_BASE_2
4、修改tomcat2配置文件,主要修改端口:
/usr/local/tomcat2/conf/server.xml
<Server port="8006" shutdown="SHUTDOWN"> #此处的8005已改为8006
<Connector port="8081" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" /> #此处的8080已改为8081
<Connector port="8010" protocol="AJP/1.3" redirectPort="8443" /> #此处的8009已改为8010
端口说明:
- 8080 默认的连接端口
- 8443 SSL的连接端口
- 8009 Apache的侦听端口
- 8005 用于停止Tomcat的端口
5、重启系统生效,#source /etc/profile没作用 6、测试 浏览器访问 http://localhost:8080 http://localhost:8081 都能看到那只猫表示正常!
修改FSTAB文件出错系统无法启动
问题的解决过程中,重新mount /是比较关键的一步(mount -n -o remount,rw /)。如果没有此步操作,则文件系统处于只读状态,导致不能修改配置文件并保存,修复存在的问题
安装SVN
出现configure: error: We require OpenSSL; try --with-openssl
需要安装openssl 和 openssl-devel
svn启动
svnserve -d -r 目录 --listen-port 端口
安装JAVA修改profile
JAVA_HOME="/usr/local/java"
JRE_HOME="/usr/local/java/jre"PATH=/usr/local/java/jre/bin:/usr/local/java/bin:/usr/local/Percona/bin:/usr/local/apache-ant-1.7.1/bin:$PATHCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JRE_HOME PATH CLASSPATH
查看当前正在删除的进程
lsof|grep delete
查看目录大小
查看目录大小
du -sh dir
显示目录下所有子目录大小
du --max-depth=1 -h dir
isolinux.cfg
default linux ks=cdrom:/anaconda-ks.cfg
#default vesamenu.c32
#prompt 1
timeout 600
display boot.msg
menu background splash.jpg
menu title Welcome to CentOS 6.3!
menu color border 0 #ffffffff #00000000
menu color sel 7 #ffffffff #ff000000
menu color title 0 #ffffffff #00000000
menu color tabmsg 0 #ffffffff #00000000
menu color unsel 0 #ffffffff #00000000
menu color hotsel 0 #ff000000 #ffffffff
menu color hotkey 7 #ffffffff #ff000000
menu color scrollbar 0 #ffffffff #00000000
label linux
menu label ^Install or upgrade an existing system
menu default
kernel vmlinuz
append initrd=initrd.img
label vesa
menu label Install system with ^basic video driver
kernel vmlinuz
append initrd=initrd.img xdriver=vesa nomodeset
label rescue
menu label ^Rescue installed system
kernel vmlinuz
append initrd=initrd.img rescue
label local
menu label Boot from ^local drive
localboot 0xffff
label memtest86
menu label ^Memory test
kernel memtest
append -
打包目录脚本
打包data目录在/tw目录下
#! /bin/bash
year=`date +%Y`
month=`date +%m`
time=`date +%Y-%m-%d_%H:%M:%S`
BACKDIR=/tw/$year/$month
mkdir -p $BACKDIR
tar -zcvf $BACKDIR/$time.tar.gz /data
echo 'End !'
关闭IPV6
vi /etc/modprobe.d/dist.conf
options ipv6 disable=1
alias net-pf-10 off
vi /etc/sysconfig/network
NETWORKING_IPV6=off
查看服务监听的IP中是否有IPv6格式的地址
netstat -tuln
查看后台任务
查看使用ctrl+z或&在后台运行的任务
jobs
将任务切换到前台
fg 12
将任务切换到后台
bg 12
使用二进制源安装后终端无命令
mysql 为例,当前终端有效
export PATH=$PATH:/usr/local/mysql/bin
永久生效
echo "PATH=$PATH:/usr/local/mysql/bin/" >> /etc/profile
防火墙打开端口
iptables
参数:
- -I 在头部插入一条
- -A 在末尾添加一条
打开80端口
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
关闭80端口
iptables -I INPUT -p tcp --dport 80 -j DROP
直接修改配置文件
vi /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
保存策略
/etc/init.d/iptables save
重启防火墙
service iptables restart
查看端口状态
/etc/init.d/iptables status
firewall
开放80端口
firewall-cmd --zone=public --add-port=80/tcp --permanent
允许192.168.1.10访问所有端口
firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address="192.168.1.10" accept' --permanent
允许192.168.2.0/24访问所有端口
firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address="192.168.2.0/24" accept' --permanent
允许192.168.1.10访问22端口
firewall-cmd --zone=public --add-rich-rule 'rule family="ipv4" source address="192.168.1.10" port port=22 protocol=tcp accept' --permanent
移除开放的80端口
firewall-cmd --zone=public --remove-port=80/tcp --permanent
移除默认的ssh策略
firewall-cmd --remove-service=ssh --permanent
移除192.168.1.10所有访问所有端口
firewall-cmd --zone=public --remove-rich-rule 'rule family="ipv4" source address="192.168.1.10" accept' --permanent
拒绝192.168.1.10访问22端口
firewall-cmd --zone=public --remove-rich-rule 'rule family="ipv4" source address="192.168.1.10" port port=22 protocol=tcp reject' --permanent
拒绝192.168.1.10访问
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.10" reject' --permanent
拒绝所有流量,远程连接会立即断开,只有本地能登陆
firewall-cmd --panic-on
取消应急模式,但需要重启firewalld后才可以远程ssh
firewall-cmd --panic-off
查看是否为应急模式
firewall-cmd --query-panic
查看打开端口
列出所有端口
netstat -ntulp
设置分辨率
显示系统分辨率选项
xrandr
设置系统分辨率
xrandr -s 800x600
设置开机启动
centos6
chkconfig servicename on
centos7
systemctl enable servicename
servicename为服务名称
创建或修改文件时间
touch file
参数:
- -a 只更改访问时间
- -c 不创建任何文件
- -d 使用指定字符串表示时间替代当前时间
- -m 只更改修改时间
将文件修改为指定时间
touch -d '2020-12-13 22:10:30' file
linux时间日期
显示当前日期时间
date
显示格式化后时间
date "+%Y-%m-%d %H:%M:%S"
修改时间
date -s 14:15:00
本月月历
cal
禁止文件修改删除
禁止修改删除
chattr +i filename
取消禁止
chattr -i filename
查看设置特殊属性
lsattr
立即生效文件
source /etc/profile
修改开机默认启动方式
centos6
vi /etc/inittab
id:3 (单用户模式)
id:5 (GUI)
centos7
查看当前的开机默认运行方式
systemctl get-default
- multi-user.target:相当于之前的更改运行级别为3,意思就是命令行
- graphical.target:相当于之前的更改运行级别为5,意思就是图形界面(graphical中文意思是图形)
设置启动方式
systemctl set-default multi-user.target
scp安装
yum install openssh-clients
top查看实时进程信息
每两秒列新一次
top -d 2
查看某个PID
top -d -2 -p3690
将top的信息进行2次,然后将结果输出到/tmp/top.txt
top -b -n 2 >/tmp/top.txt
查看linux系统信息
uname
参数:
- -a 显示所有信息
- -r 显示版本号
- -n 显示主机名
显示用户过去命用的命令
history
查看文件内容
head -n file
tail -n file
n需要查看的行数 file查看的文件
ftp
get 文件名 下载
put 文件名 上传